Is this the end of the Age of Monochrome Illustration?
I painted the illustration frame above many years ago using the “standard” comic strip technique; black ink applied onto white card with a brush. At the time, I gave no thought to the idea that that technique might become outdated, and even within my own lifetime.
I first learned to use the brush-and-ink technique myself while at university, although I received no formal training in it. I basically figured it out by making several visits to an exhibition of illustrative artwork that displayed work done for the BBC’s house magazine Radio Times. The exhibition took place at the Victoria & Albert Museum, which was just around the corner from Imperial College, and thus was very convenient for me. The front cover of the exhibition catalog is shown below.
Art of Radio Times Exhibition Catalog
Following that exhibition, my first attempt to use the brush-and-black-ink technique was to illustrate a poster for a lecture titled The Psychology of Gambling. My poster illustration is shown below.
Psychology of Gambling
It was also my responsibility to prepare the print masters for my posters. When preparing the master for the poster above, I learned a valuable lesson about the use of solid expanses of black! Although they do make for a striking design, half-screen reproduction processes didn’t handle them well, so they were best avoided in those days. (Modern printing techniques are less prone to this kind of problem, but it’s still something to bear in mind.)
Ian Ribbons
Recently, I wrote an article about my experiences in an Illustration class that I took at St. Martins School of Art, London, way back in 1982. My tutor for that class was Ian Ribbons, who (unbeknown to me at that time) was a fairly famous British illustrator. (I find it sobering to reflect that he may have been the only art teacher I ever had who was a noted artist in his own right.) My experience in that class, and Mr. Ribbons’ guidance, were immensely helpful to me in developing my own styles and approaches to art projects.
Years later, while browsing in a secondhand bookshop, I came across a copy of a 1963 book by another famous British illustrator, Robin Jacques, in which he compiled biographies and work samples of many contemporary artists (one of whom was Ian Ribbons, which was what drew my attention to the book). The book is called Illustrators at Work, and the front cover is shown below.
Monochrome vs. Black-and-White
The notable but unspoken common characteristic of every art sample in the Illustrators at Work book is that it is not only shown in monochrome (or grayscale in computer terms), but was specifically produced for monochrome-only reproduction.
(Such artwork is typically called “black and white”, but that’s not strictly accurate because much of it includes shades of gray. Here, I’ll use “black and white” to refer only to artwork that literally uses only those two colors, and does not include grays. I’ll use “monochrome” to refer to artwork that consists of gradations from one color—usually black—to white.)
That fact made me think about how much art, illustration and reproduction methods have changed during my lifetime. For most of the twentieth century, it was taken for granted that most artwork for printed reproduction would be monochrome, primarily for economic and technical reasons. Most books, newspapers and magazines were printed entirely or mostly using only black ink, so there was no possibility of reproducing anything in color.
Why Does Monochrome Work?
I notice that very few people stop to consider why we accept some monochrome images as being valid two-dimensional representations of a scene, when we would not accept certain other kinds of monochrome images.
For example, for many years most photographs were monochrome (“black and white”). Provided that the grayscale in the image corresponds to that of the actual scene, the human brain accepts it as valid and can interpret the content, for example by recognizing a face.
However, if the grayscale in the image does not correspond to that in the real scene, the brain cannot interpret it correctly. For example, if shown a monochrome photographic negative, most people would have difficulty identifying a face that they would immediately recognize if shown the corresponding positive image.
Why is this the case?
I described in a previous post how the human visual system relies on various types of light receptor cells within our eyes. One type are called “Rods”, and these provide us with monochrome vision in low light conditions. It is because of this ability that we accept a monochrome image as being a valid representation of a scene; our brains just assume that we’re looking at something in low light.
Reproduction of Illustrations
Until the twentieth century, illustrations that were intended for printed reproduction were often produced using intaglio techniques. This involved the creation of the illustration by literally incising lines onto a metal or wood surface, and thus all shading had to consist of patterns of lines or dots. Perhaps one of the most famous masters of this technique was Sir John Tenniel, who illustrated Lewis Carroll’s “Alice in Wonderland” and similar works.
Last year, I parodied Tenniel’s style to produce a satirical image of a well-known politician throwing a characteristic temper tantrum. Tenniel’s original images of Tweedledum and Tweedledee, which inspired my image, were woodblock cuts, but mine is a pen-and-ink drawing.
Tweedle Don
Limitations Stimulate Creativity
The restriction to a single color, and the inability to print continuous shades of even that one color, forced artists to develop many sophisticated drawing techniques that used black and white patterns to simulate continuous tones, such as cross-hatching and stippling.
My Tenniel parody above shows samples of cross-hatching, whereas the image below shows a sample of stippling, in my never-finished portrait of the young H G Wells.
Unfinished Portrait of H G Wells
I mentioned above one artist who excelled in such techniques, Robin Jacques. His artwork has appeared in many children’s books and is justly world-famous. Another master of the art was Eric Fraser, whose work appears on the cover of the Art of Radio Times exhibition catalog shown above.
Frank Patterson’s Linework
A less famous artist who excelled in monochrome illustration, and particularly in the use of linework, was Frank Patterson, most of whose work was produced for British cycling magazines from the 1920s through the 1940s.
The illustration of a road across Haworth Moor (shown below) is a spectacular sample of how Patterson could create a dynamic and emotive scene merely from black lines. This is clearly one of those cases where a photograph of the scene would probably be far less effective than the artist’s imaginative creation.
Haworth Moor. Copyright Frank Patterson
Conclusion: The Brave New World of Full-Color Illustration
As I mentioned above, the situation now is that, in most publications, there are no restrictions on color reproduction at all. Every image can be reproduced in full color at no additional cost, relative to monochrome reproduction.
While this opens up new creative possibilities for artists, it does mean perhaps that we will never again see the development of ingenious new techniques for monochrome artwork.
This article describes techniques for capturing the screen image of devices using various operating systems, such as Windows, Android, Linux, etc. Most computer users don’t realize that all Operating Systems have built-in functionality to achieve this.
Even if you’re not writing computer documentation or producing artwork, the ability to capture a static image of the screen you’re viewing, or even a video, is a very useful skill. For example, you may want to capture the text of an instant message from the screen of your smartphone, to provide written proof of what messages were actually exchanged during a dispute (which you’ll need when you appear in front of Judge Judy!).
As I said, all Operating Systems have built-in functionality to achieve this, so additional tools are usually not required. However, the feature is partially hardware-dependent, so techniques vary according to the available user interface controls of the device.
I’ll also discuss a few pitfalls of the screen capture process. I’ll show you how you can reduce the size of a captured dialog image without also reducing its quality.
What is a Screen Capture?
As I mentioned in a previous post, when you’re viewing the display of any modern computer, tablet or smartphone device, you’re actually looking at a bitmap image. Therefore, surely it should be possible to copy that bitmap into a file and save it for later use. In principle this should be easy, but in practice there are cases where computer manufacturers and software developers can make it difficult, either intentionally or otherwise.
In most cases, the device’s Operating System provides built-in techniques that you can use to perform screen captures.
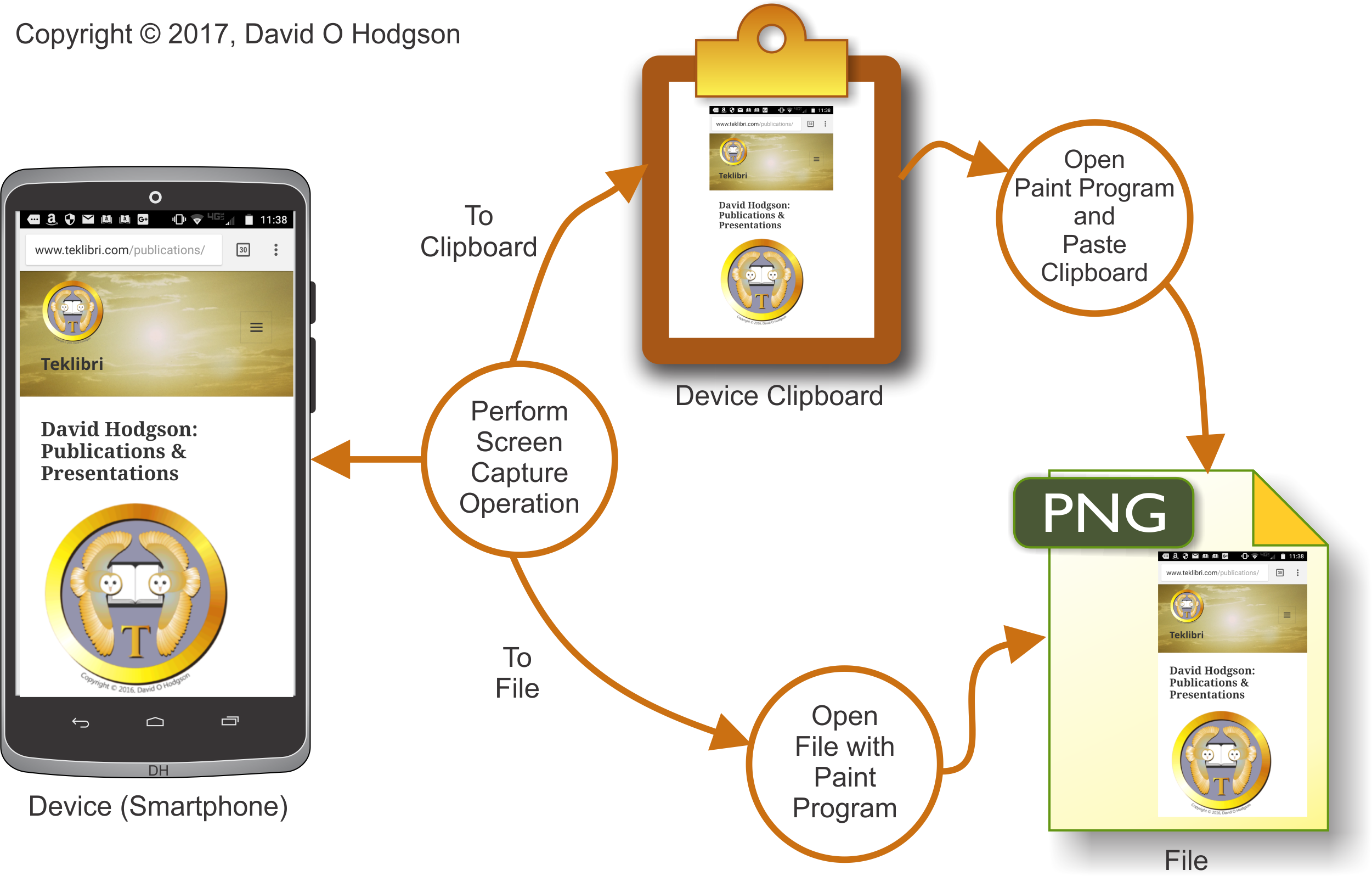
An example of the basic screen capture process is shown in the diagram below.
General Screen Capture Process
As shown in the diagram above, you perform the screen capture operation according to your device’s operating system, which copies the screen bitmap either to a file, or to an area of memory called the Clipboard. If the bitmap was copied to the Clipboard, you open a Paint program and paste it into a blank image. If the bitmap was copied to a file, you can open that file with your Paint program, as you would for any other bitmap image.
(Note: I changed the file type in the diagram above to “PNG” from “JPEG” because, as I explained in my previous post on Mosquitoes, JPEG usually is not a good format choice for saving screen capture images.)
You can also purchase third-party tools to perform screen captures, but many of these simply take advantage of users’ ignorance of the capabilities that are already built into the operating system, and hence available free of charge. Some screen capture utilities do provide additional capabilities; there’s nothing wrong with them, but it’s smart to be aware of what you can do without additional software or cost.
The Two Types of Screen Capture
There are two types of screen capture:
Static. Grab a single bitmap image of the screen content.
Video. Record a segment of screen activity as a digital movie.
Note that, in this article, I’m not specifically discussing the concept of capturing a frame image from a movie that you happen to be watching on your device. While you can use the techniques described here to capture such frames, it’s usually easier to use functionality provided with your video viewing software (such as, for example, Cyberlink PowerDVD).
A Little History
When I started developing Windows software, in the early 1990s, I was creating step-by-step tutorials describing computer setup, so I needed to include many screen captures. I understood what I needed to do, but I didn’t know how to do it, so I searched for screen capture tools. Several were on offer, costing from $70 upwards. However, I soon discovered that Windows came with a built-in screen capture function, which was thus available for free. You simply press the Print Screen key on the keyboard, which causes the screen image to be pasted to the Windows clipboard. Then, you can paste the clipboard image into any bitmap editing program.
Since then, I’ve spent more than a couple of decades developing software, much of which has been for some version of Windows, and it amazes me how many experienced Windows users and developers still don’t know about the Print Screen function! I see people still buying expensive commercial tools, simply to do something that their Operating System can already do.
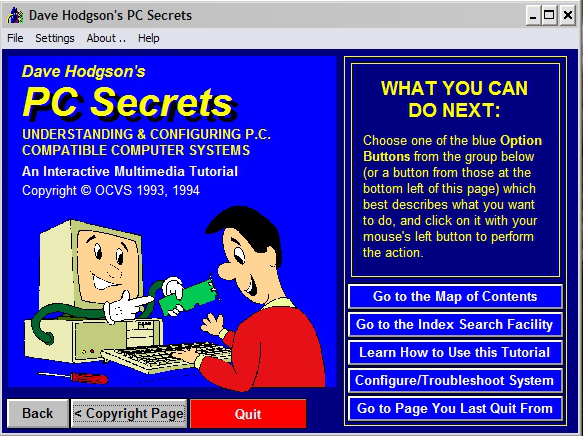
PC Secrets Title Screen
The image above shows a screen capture of the title screen of one of my early “multimedia” productions (“PC Secrets”). I admit that, with the benefit of hindsight, it looks very garish and crude! Bear in mind, though, that given the state of technology at the time, screens had to be readable on monitors that could display only sixteen colors.
Legal Issues & Image Downloading
Most people are aware of the copyright issues that attach to the copying of on-screen images. In principle, just about everything that is displayed on-screen is subject to someone’s copyright. In practice, however, copyright concerns arise only in connection with images that are regarded as having value, such as photographs or artwork.
This article describes techniques for image capture from the device’s display itself, as opposed to the downloading of images from web sites. However, since any image that you download from a web site can be displayed on your device’s screen, you can obviously use screen capture to create copies of downloaded images.
If you can see an Image, you’ve Downloaded it!
You’ll probably encounter some web sites that go to considerable trouble to try to prevent you from downloading images (typically those that display photos or artwork). This has always seemed laughable to me, because, if you’re looking at the image on-screen, then you have already downloaded it! It seems that the web site owners simply hope that their users are too ignorant to know that, or that this was a requirement specified by some manager or “marketing type” ignorant of how computer display technology actually works.
Types of Capture
Static Bitmap
This technique allows you to grab a static bitmap, containing the content of your device’s screen at one instant in time.
All modern operating systems with a graphical user interface provide a built-in means of doing this.
Video
This technique allows you to record a movie of your device’s screen. The movements of anything on the screen while you were recording will be replicated in the movie. This is very useful if you want to create a movie showing computer users how to perform a task.
Most operating systems do not include built-in video recording capabilities, but Windows 10 does now offer such a feature, as described below. If your operating system does not offer video recording capabilities, you can buy third-party tools to add the functionality.
Native Capture Capabilities by Operating System
Screen capture is an area where procedures are heavily dependent on the operating system that you’re using. For example, knowing how to perform a screen capture on a Windows PC is useless when you want to grab the screen of an Android phone. For this reason, I’ve grouped the information below according to operating system.
Note that my practical experience is mostly limited to Windows and Android systems, so, for other operating systems, I’ve taken the information below “on trust” from other sources. Please let me know if something below is inaccurate.
Windows
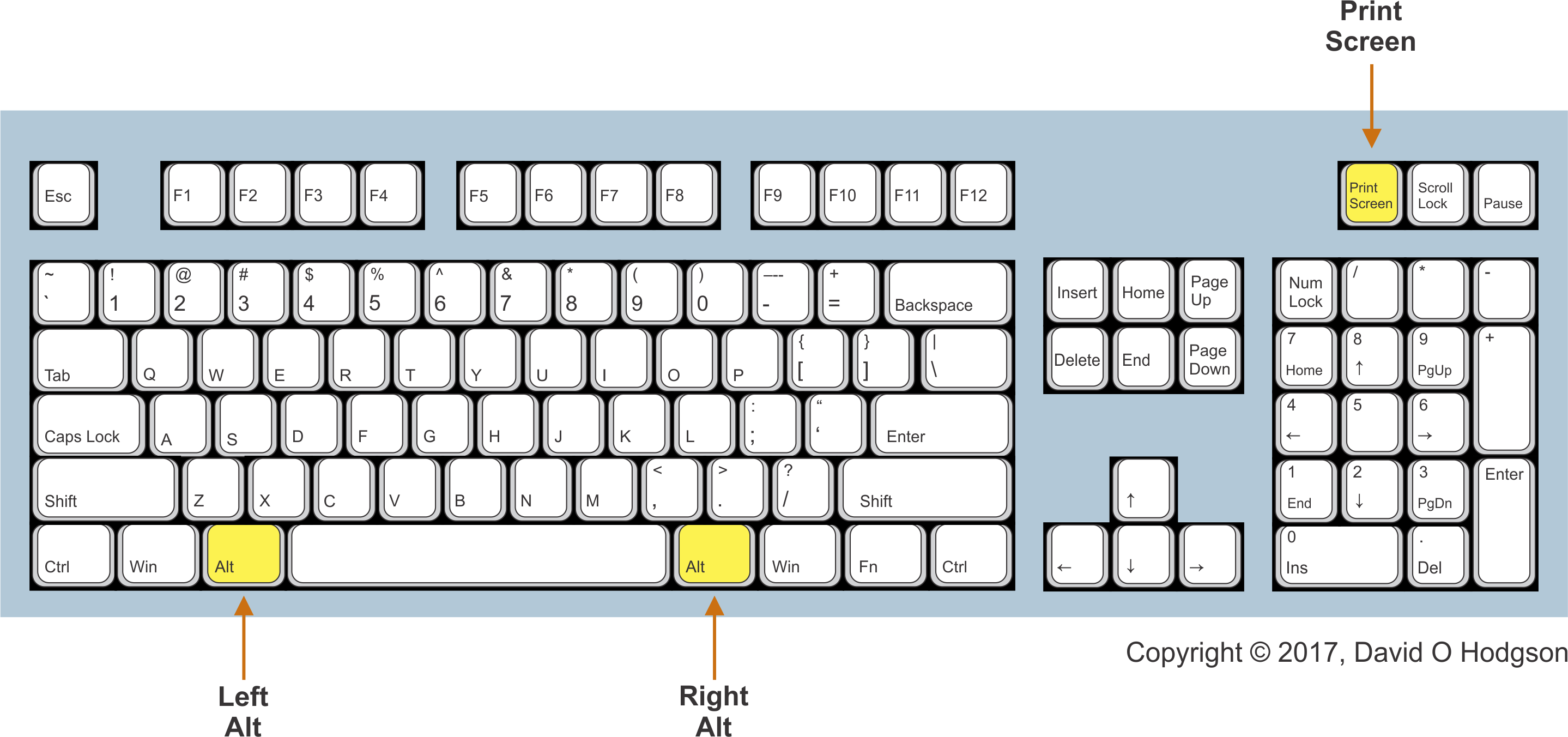
To copy the entire screen area to the clipboard, press the Print Screen key. Note that, if your system has multiple screens, the captured bitmap will span all screens.
To copy the active window to the clipboard, press the Alt+Print Screen keys simultaneously.
After pressing one of these key combinations, open a bitmap editing program (such as the built-in Paint program), then press Ctrl+V to paste the image into the program. You can then save the image as a bitmap file.
The positions of the Left Alt and Right Alt keys, and the Print Screen key, on a typical PC keyboard are as shown below. Typically, whenever a key combination requires use of the Alt key, you can press either the Left Alt or Right Alt keys.
PC Keyboard: Alt and Print Screen key positions
Windows 10
One of the less well-known improvements in Windows 10 is that it offers some new screen capture capabilities, in addition to those described above that existed in previous versions of Windows.
To save a copy of the entire screen to a file in the Screenshots folder, press the Win+Print Screen keys simultaneously.
To save a copy of the active window to a file in the Screenshots folder, press the Win+Alt+Print Screen keys simultaneously.
Video: for the first time, Windows offers a built-in screen recording capability, via the Game Bar. This feature is primarily intended for video game players, but it can also be used as a basic screen video recorder.
Apple (iOS)
I haven’t verified these instructions, which are provided on Apple’s iOS Support site, at:
Press and hold the Sleep/Wake button on the top or side of your device.
Immediately press and release the Home button.
To find your screenshot, go to the Photos app > Albums and tap Camera Roll.
Android
If your smartphone is manufactured by Motorola, Samsung, or one of many others, then it probably uses Google’s Android operating system.
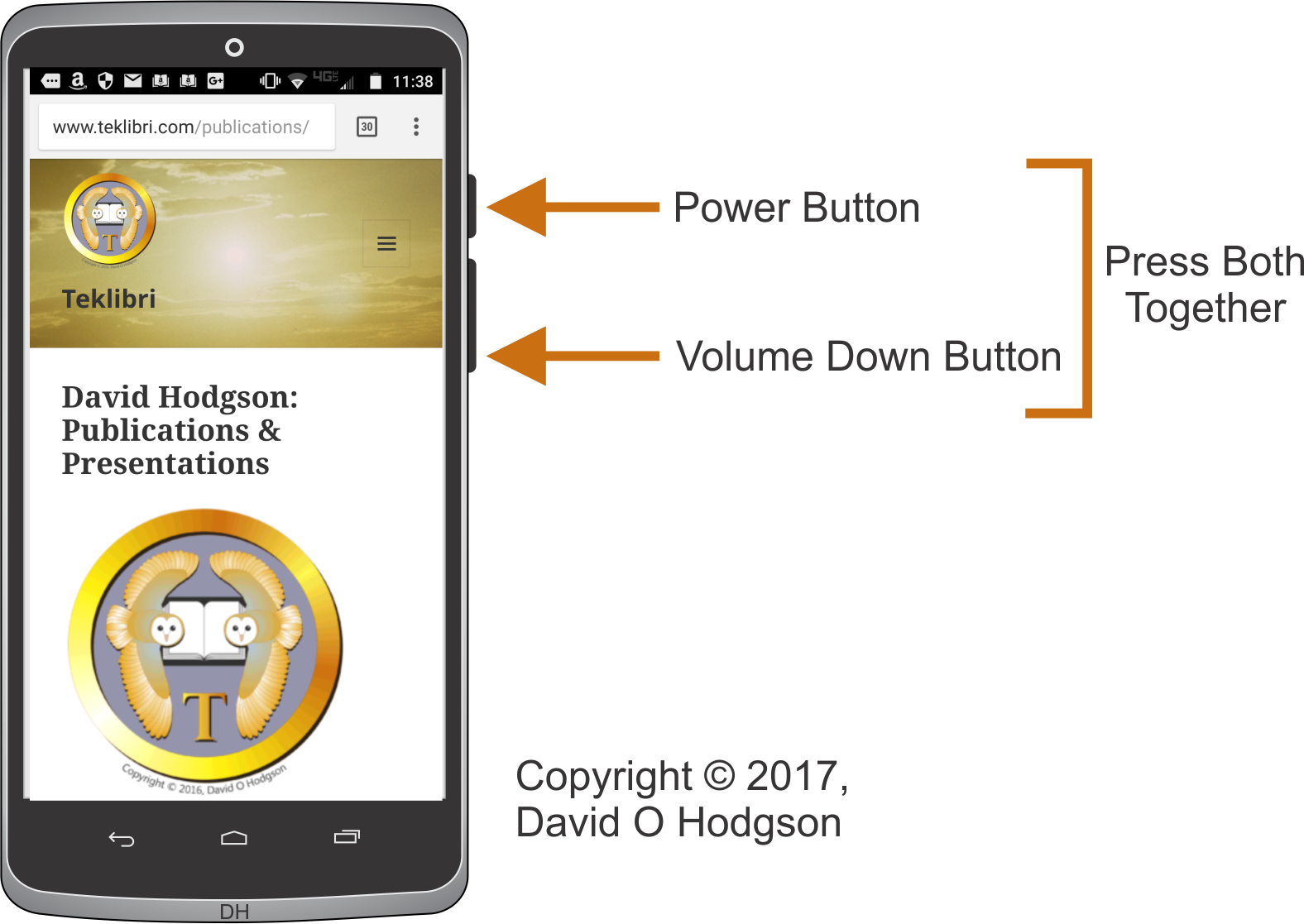
The obvious problem with screen capture in such devices is that they tend to have very few off-screen controls. If you tried to use software to perform a screen capture, then you would obscure part of the screen image that you want. Thus, screen capture usually has to be performed using some combination of the device’s available physical buttons.
Android Screen Capture Process
For devices from many manufacturers, you perform a screen capture by pressing the Power and Volume-Down buttons simultaneously.
This is actually quite tricky to do, and takes some practice.
If you don’t press both buttons at the same time, you’ll end up turning off the device!
HTC, LG, Motorola, Nexus, Sony
Press and hold Power and Volume-down buttons together. A bitmap containing the screen image is created in the Screenshot folder.
Alternatively, for Sony devices only, you can tap the Power button to access options to take a screenshot or screencast in the Power options menu.
Samsung
Press and hold Power and Home buttons together.
Alternatively, enable the ability to take a screenshot with a palm swipe in Settings, Motions & gestures, Palm swipe to capture.
Linux
The basic functionality is similar to that provided in Windows:
Print Screen key: Copy the entire screen area to the clipboard. Note that, if your system has multiple screens, the bitmap will span all screens.
Alt+Print Screen keys: Copy the active window to the clipboard.
Alternatively, you can use the Gnome-screenshot utility, which is part of the GNOME Desktop Environment.
Screen Capture Handling Pitfalls
Once you’ve obtained a “raw” screen capture bitmap, there are various ways that it’s likely that you’ll want to manipulate it. In general, you can use standard bitmap image processing tools and operations for screen captures. Standard tools include Microsoft Paint (included with Windows), Adobe Photoshop, Corel PhotoPaint, etc.
However, there are some additional considerations that can trap the unwary.
Including the Cursor
Generally, the screen cursor is not included in a screen capture. This is usually convenient, because you don’t want an arbitrarily positioned cursor in your image. In cases where you do want to show a cursor in the image, you can paste this in using a paint program later on.
Resizing the Image without Rescaling
I’ve seen many cases where a technical writer uses a screen-captured image in a help publication, but then resizes (reduces) the screen image to fit in some available space, and is surprised and disappointed when the resulting image appears “fuzzy” and sometimes unusable.
Here’s a small example where I’ve deliberately emphasized the poor results that occur when you try to reduce the size of a screen image containing text.
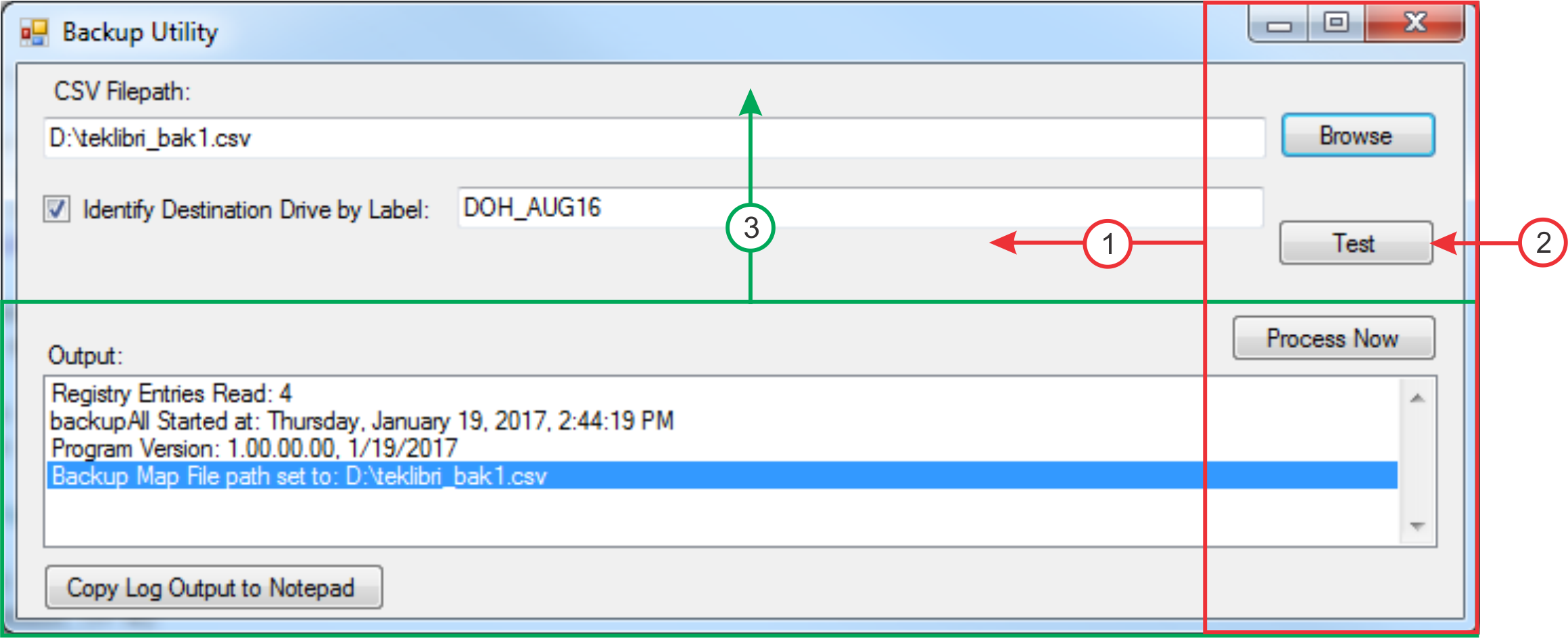
Here’s a dialog that I captured for documentation purposes:
Resizing a Captured Dialog
But the dialog was too large to fit in my document, so I resized it to 50%:
Dialog reduced to 50%
Oh dear! As is obvious, the crisp text in the original image has now become so blurred that it’s almost unreadable. This would be of very limited value in documentation, and it definitely looks unprofessional. I’d be embarrassed to publish an image like this (except for the purposes of this counter-example).
The simple reality is that operating system manufacturers have put a lot of effort into optimizing the appearance of the screen at the intended size and resolution. These screens are not designed for resizing by interpolation methods.
Resizing without Interpolation
So, if I’m writing documentation and I simply have to make a screen capture image smaller, what can I do? One technique is to use the cut-and-paste features of your paint program to “squeeze up” the important parts of the dialog, so that the controls I want to discuss are still visible, but empty portions of the dialog are omitted. Here’s an example of that technique, applied to the dialog image above:
Dialog Resized without Quality Reduction
Notice that I moved the buttons at the right over to the left, and removed the “Test” button completely. I also moved the lower part of the dialog upwards, eliminating the blank gray area in the original. All the changes here were made in the paint program: I didn’t make any change to the display of the original dialog in the software. Because the dialog image has no noise, I was able to move around the elements seamlessly.
Here is the sequence of operations to resize the dialog as above:
Dialog Resizing Operations
Cut the red rectangle, move it left, and paste it.
Paint out the Test button
Cut the green rectangle, move it up, and paste it.
Trim the entire image to its own new border.
Third-Party Tools
This article does not attempt to offer a comprehensive review of available third-party screen capture utilities. The following is a list of some commonly-used utilities, without any comment as to their quality or features.
This article explained how the ability to capture an image of the screen, or (in some cases) a video of activity on-screen, is built into all modern operating systems. Even without third-party add-ons, you can capture and save screen images from any device.
Now you are armed with the knowledge of how to capture screen images from all your devices! You will never again have to offer up to Judge Judy the lame excuse that “I can’t show you that because my computer/tablet/phone broke”!
When you perform a rotation operation on a bitmap image, such as a digital photograph that you’re trying to straighten, you may sometimes create an undesirable effect called staircasing, where what were apparently straight and smooth edges in the original image become noticeably “stepped” in the rotated result. I noticed this problem recently when I tried to correct a shooting error in the image above (the version above shows the corrected image).
Generally, whenever someone takes a photograph of a natural scene, they attempt to align the camera so that the ground line will appear exactly horizontal, and so that vertical edges in the scene will be truly vertical in the image.
However, the photographer doesn’t always achieve this, and that is becoming a more frequent problem in these days of smaller cameras. When you’re holding up your phone camera, it can be very difficult to ensure that it is exactly perpendicular to the horizon.
There are apps that you can install on your phone that display a “torpedo level” widget, so that you can determine when your device is exactly horizontal, but most people don’t use such apps. In any case, once a photo has been taken, you usually can’t go back and take it again.
Below is an example of an image where what should be vertical edges are not quite vertical, due to the angle at which the camera was held when the photograph was taken. I took this photo in London in 1981, and since then many of the buildings in the picture have been demolished, so there’s zero chance of being able to retake the photo!
Uncorrected Image
If you look closely at the image above, you can see that what should be a vertical edge nearest to the centerline of the picture is not quite vertical. It’s tilted about 1° counter-clockwise. In theory, it’s easy to fix this by rotating the entire image 1° clockwise. However, if this is not done carefully, staircasing effects can result.
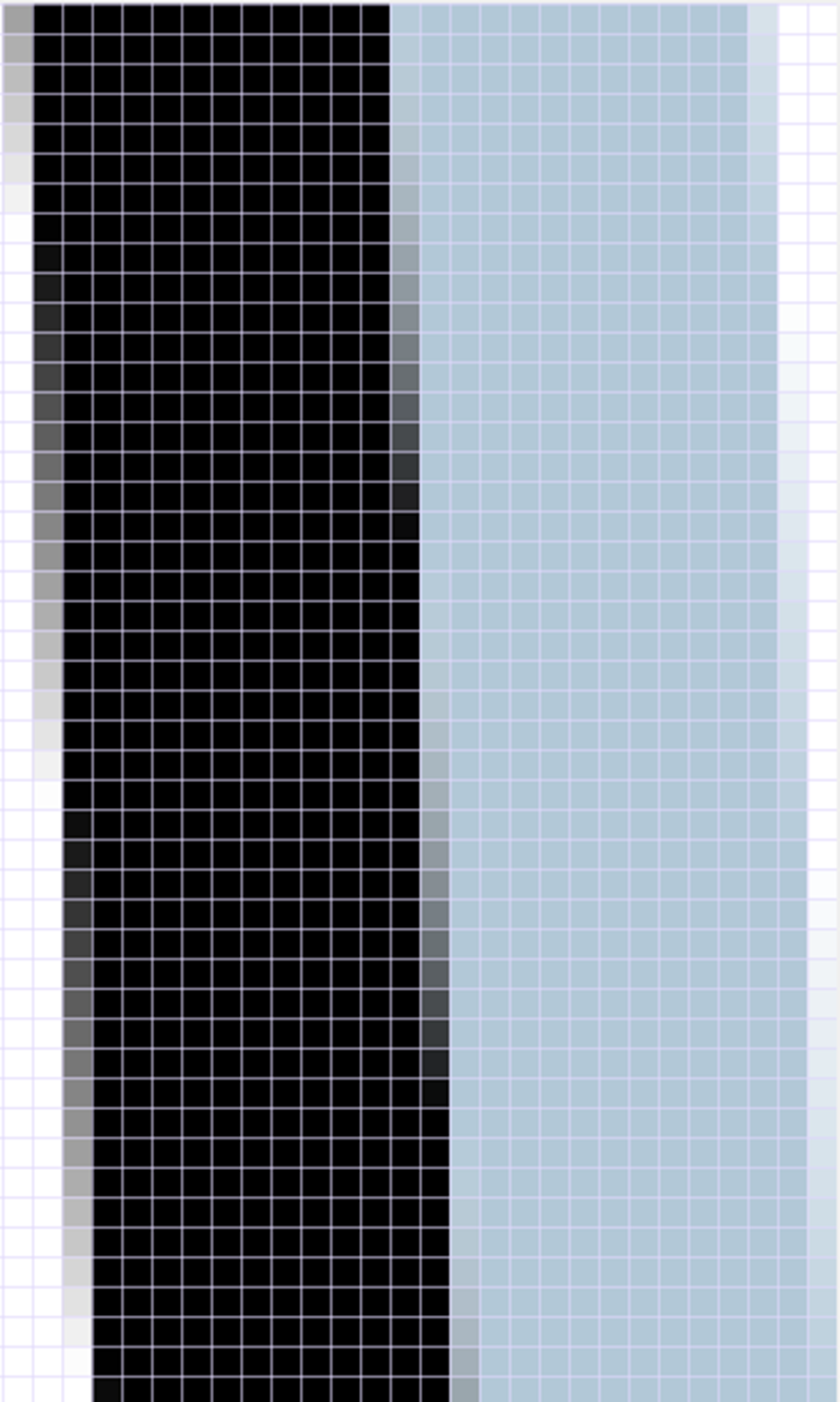
Below is an example of visible staircasing in a portion of the rotated image, resulting from an attempt to straighten the verticals in the original. (This is an enlargement to show the effect.) Notice the jagged transitions where the bright lamps contrast with the dark background.
Staircasing Effect in Bitmap Image
How can you avoid this undesirable effect? Below, I offer a couple of solutions, but it’s important to bear in mind these overriding principles:
Except for rotations in multiples of 90°, you should avoid rotating images unless absolutely necessary, because most rotations result in loss of detail.
If you must rotate an image, perform only one rotation to achieve the final result, because each individual rotation introduces errors. For example, if you want to rotate your image by 3°, do that as one 3° operation rather than three consecutive 1° operations.
Staircasing: the Cause
As I explained in an earlier post, when you take a digital photograph, your camera creates a rectangular bitmap matrix of colored “dots” or pixels. The color value of each pixel is determined by the color of light shining on that particular detector in the sensor.
If you subsequently want to change the mapping of the color values to the bitmap matrix, as happens if you want to resize or rotate the image, then there has to be a way to determine the new color value of each pixel in the modified image.
The simplest way to determine the new color value of each pixel is simply to pick the value of the nearest corresponding pixel in the original image. (This is called Nearest-Neighbor Interpolation.) However, in areas of the image where there are sharp transitions of color, this method can lead to jagged edges and the effect called Staircasing.
(If you rotate a bitmap through some exact multiple of 90°, then this effect does not appear, because the original rectangular matrix maps exactly to a new rectangular matrix. The discussion here relates to rotations that are not a multiple of 90°.)
The following example shows a simple case of this problem. In these images, I’ve deliberately enlarged everything to the point that you can see the individual pixel boundaries; you would rarely see these at normal viewing magnifications. I’ve also tilted an edge that was originally vertical into a non-vertical position, rather than vice versa, because this shows the effect more plainly.
In the first image, on the left is the original unrotated image, which consists only of a dark rectangle abutting a light-colored rectangle. The transition between the two colors is a vertical edge, which maps neatly to the vertical alignment of the pixels.
Rotation of Bitmap without Interpolation
On the right above is the result of rotating this image by 1 degree counter-clockwise, without any interpolation. Each new pixel takes the color value of the nearest pixel in the original image. Since the transition between the colors no longer maps neatly into vertically-aligned pixels, a jagged edge transition has now been created.
To reduce the quantization effects, a more sophisticated way of determining the new pixel values is by interpolation. Interpolation is basically a sophisticated form of averaging, whereby the color value of each interpolated pixel is determined by averaging the values of the nearest few pixels in the original image.
Here’s the same rotation operation, but with interpolation applied:
Rotated Bitmap with Interpolation
As you can see, the jaggedness is reduced, although there are still visible discontinuities, due to the small number of pixels involved.
Staircasing: the Solution
As demonstrated above, the staircasing effect is caused by inadequate interpolation of color values between adjacent pixels in a bitmap. If the interpolation could somehow be made perfect, the problem would not occur.
Typically, when we rotate an image, we’re using third-party software, and we’re stuck with whatever interpolation algorithm has been provided by the software manufacturer (which may consist of no interpolation at all). Thus, we can’t improve the interpolation, so all we can do is to take steps to disguise the problem.
Whenever you notice staircasing in a rotated image, the first thing to check is whether interpolation was applied during the rotation operation. Depending on the software you used to perform the rotation, interpolation may not have been applied by default, or, in the case of some low-end software, it may not even be available.
Look for an “interpolation” setting in your software. In some cases, this is referred to as “anti-aliasing”, even though there isn’t really any “aliasing” in this case. Make sure that “interpolation” or “anti-aliasing” are switched on.
Solution #2: Increase Image Resolution
If using interpolation doesn’t work, then the second approach is to try to reduce the quantization artefacts by temporarily increasing the Image Resolution. Most modern bitmap processing (“Paint”) software allows you to do this quite easily.
The procedure is as follows:
Use your paint software to increase the image DPI. To minimize the amount of unnecessary interpolation required, it’s usually best to set the new DPI value to be an exact multiple of the current value. For example, if the image currently has 72 DPI, try increasing to four times that (288 DPI), or another higher multiple. (In general, the higher the DPI, the better, but of course increasing the resolution increases the total image size, so processing takes longer and requires more memory.)
Perform the rotation operation.
Reduce the image DPI back to the original value.
Evaluate the results. If staircasing is still visible, repeat from Step 1, but this time increase the image DPI to an even higher multiple of the original.
Use Your Own Judgment
Ultimately, fixing this problem is a matter of aesthetic judgment; you have to view the results and decide when they’re good enough. What’s good enough in one situation may not be good enough in another.
I hope that my explanation has been helpful, but, if you need more detail, here is a very good post describing these concepts.
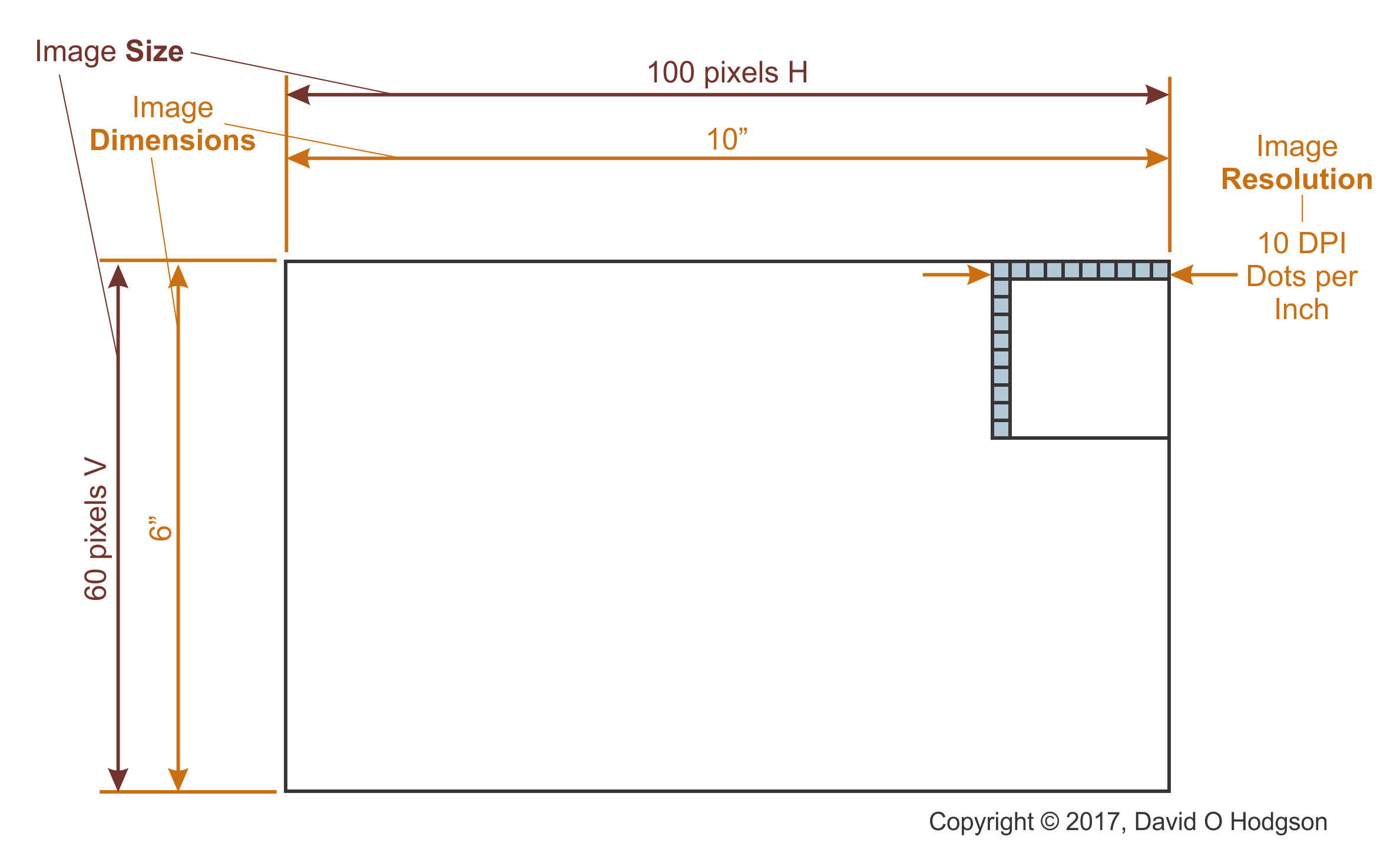
Definition: Image Size, Dimensions and Resolution
It may be helpful to remind ourselves of the differences between bitmap image size, dimensions and resolution. In my experience, these important distinctions can cause immense confusion to people working with bitmap images. That is not helped by the fact that some of these terms are used loosely and interchangeably in existing documentation, which merely adds to the confusion.
Each pixel in a bitmap image has a constant color value. The illusion that the colors in the image vary continuously occurs because the image typically consists of a very large number of pixels.
It’s intuitively obvious that each bitmap has a particular “size”, but what exactly does that term mean in this context? There’s more to it than just the number of pixels in the matrix, because that does not specify the size at which the bitmap is supposed to be viewed.
Note that these are my definitions of the terms, and you may find varying definitions in other documentation. The important point is to understand what is meant by each term, rather than which term is used for which concept.
Definitions
Image Size: The width and height of the image (W x H) in pixels
Image Dimensions: The width and height of the image (W x H) in measurement units
Image Resolution: Dots Per Inch. It is possible for an image to have different horizontal and vertical DPI values, but this is rarely done in practice. The horizontal and vertical resolutions are usually the same.
Definition: Interpolation
Interpolation is a mathematical concept, which involves creating new data points between the data points of an existing set.
When applied to images, interpolation usually involves creating a new pixel color value by averaging the values of nearby pixels, according to some algorithm.
Ballpoint Pen Illustration of Pallab Ghosh as “Super-Editor”
This article describes some figure drawing techniques for human figures. Even in technical illustration tasks, it’s sometimes desirable to be able to include human figures. However, depicting human figures accurately can be time-consuming, so I’ll suggest some time-saving options.
I will discuss:
Realistic drawings or paintings for “finished” artwork,
Figure sketching for storyboarding,
Cartooning as a way of producing acceptable representations quickly.
Learning to draw is itself a complex skill, and drawing the human figure is perhaps one of the most demanding tasks any artist can face. I’m aware that many entire books have been written on the subject. There are also many books on the subjects of cartooning and storyboarding, so this will be a very cursory overview of my own experience. Nonetheless, the techniques I offer here may be helpful if you need to create such artwork.
The illustration at the top of this article is part of a poster that I produced for Pallab Ghosh, who was at that time a fellow student at Imperial College, London. It was drawn entirely using black ballpoint pens, then scanned to make the final poster. There are more details about this drawing below.
To develop and maintain my skills, I frequently attended “Life Drawing” sessions, which typically involve drawing or painting a live human model.
Figure Drawing: Pencil Technique
Largely as a result of my experience at Life Drawing sessions, I evolved a standard technique for pencil drawing. I prefer to draw in pencil because it is relatively fast, and requires minimal preparation and materials, while still allowing for some correction of errors. The from-life drawing below shows an example of this technique, from a session at Cricklade College, Andover, UK.
Life Drawing Sample in Pencil
It’s usual for models in Life Drawing classes to pose nude, and this was the case for the drawing above. Therefore, I’ve cropped the image so that it won’t be “NSFW”!
Speed is of the essence in life drawing sessions, because live models cannot hold their poses indefinitely. Even in a very relaxed pose, most models need a break after an hour, and most poses are held for only five to thirty minutes. Therefore, even though my technique allows for the correction of errors, there is usually little time to do that.
My pencil technique certainly does not follow “conventional wisdom”, and in fact I have found some standard advice to be counter-productive. The details of my technique are:
Pencils. I find it best to use an HB “writing” pencil instead of the usually-recommended soft drawing pencil. I find that the softer pencils wear down too quickly, and that their marks have an annoying tendency to smudge. Eagle writing pencils seem to have smoother graphite than so-called “drawing” pencils, which provide a more uniform line.
Paper. I use thin marker paper rather than heavy Bristol board or watercolor paper. Again, the smooth surface of the marker paper allows for more subtle shading effects, because the pencil line does not “catch” on irregularities in the paper surface.
Sharpening. I don’t use a pencil sharpener. Instead, I sharpen my pencils by carving off the wood with a knife, leaving about 5mm of graphite projecting, then rub the tip to a point using sandpaper. This is a technique that I actually learned at school during Technical Drawing O-level classes. The benefits are that I don’t have to sharpen the pencil so frequently, and can adjust the shape of the point to provide either a very fine line or a broader “side” stroke.
Figure Drawing Techniques: Artwork for Scanning
It sometimes seems that there’s an attitude that “pencils are for sketching only”, and that it’s not possible to produce “finished artwork” in pencil. Hopefully, the sample above will demonstrate that that’s not true.
However, it is true that pencil artwork can be difficult to scan. Even the darkest lines created by a graphite pencil are typically a dark gray rather than true black, so there is often a lack of dynamic shading range in a pencil drawing.
Reproducing printed versions of continuous-tone images requires application of a halftone screen, and such halftoning typically does not interact well with the subtleties of pencil shading.
To solve these scanning and printing problems with early photo-reproduction equipment, I developed a “pencil-like” technique using black ballpoint pen, and used it in the poster portrait shown above.
Pallab was standing for the office of Student Newspaper Editor, and, for his election poster, he wanted to be depicted as Superman (his idea—not mine!). It was of course important that the illustration would be recognizable as being Pallab. It was also important that the artwork I produced be:
Monochrome,
Easy to scan using the Student Newspaper’s reproduction camera.
It’s not particularly obvious from the reduced-size reproduction of the portrait above, but in fact there are no shades of gray in the drawing. The drawing consists entirely of fine black lines, which could be scanned and printed without requiring a halftone screen.
Figure Drawing Techniques: Storyboarding
If you’re working in advertising or video production, Storyboarding may form a significant part of your work. This involves sketching out the scenes of an advertisement or other video in a comic strip format.
Recently, I’ve also seen the use of the term “Storyboarding” in connection with Agile software development, where it’s used to describe a task sheet. Even though I have substantial software development experience myself, I’m a little cynical about this usage, because it seems like it’s just a way to make a simple and unremarkable concept sound “hip” and exciting. Anyway, that usage is not what I’m referring to here!
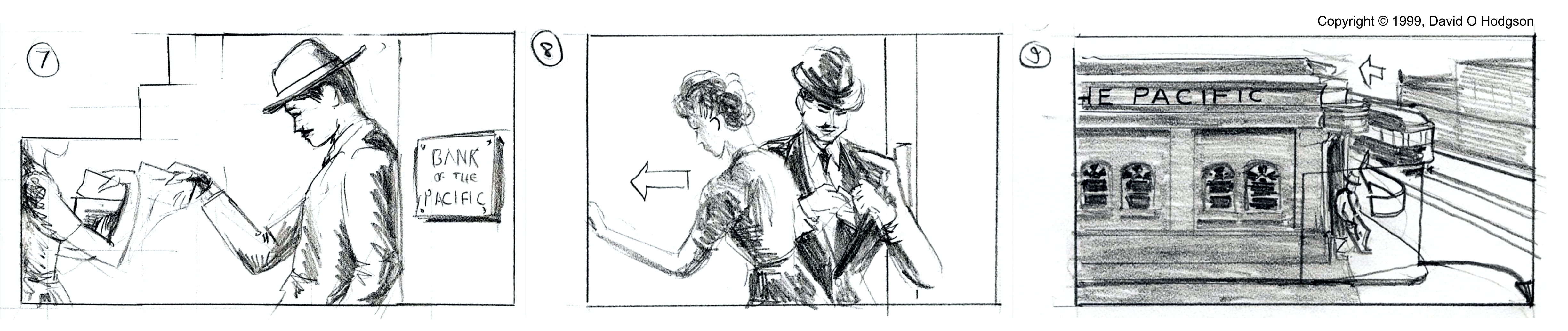
Probably the earliest use of the storyboarding technique was for movies. Every scene of a planned movie would be drawn out, showing the content of the scene, movement of actors, camera movements, and so on. Some directors created immensely detailed storyboards, Alfred Hitchcock being perhaps the best-known.
Several years ago, I attended a Storyboarding workshop at the American Film Institute in Los Angeles, presented by Marcie Begleiter. Marcie went on to write the book on storyboarding: “From Word to Image”. The AFI workshop gave me a chance to practice producing storyboard artwork, in pencil, “on the fly”. A sample extract from one of the storyboards that I produced during the class is shown below. This was drawn from memory, without reference material of any kind. The script from which I was working was for a 1940s-era film noir story, hence the period costumes and transport.
Sample Storyboard Excerpt
Storyboards are usually not intended as finished artwork, of course, as is the case for the sample above. They are used as “working drawings”, from which a final video, movie or even comic strip will be created. However, this type of artwork does call for rapid figure drawing skills, and storyboard illustrations can sometimes later be worked up as finished pictures in their own right.
Figure Drawing Techniques: Cartooning
Fortunately, there’s a way to represent the human figure that is generally much quicker, and doesn’t require precise drawing skills.
The human brain has evolved great acuity in the recognition of human facial features and other details of the human body. Even people who themselves have no drawing skills are intuitively good at discerning the smallest differences between human faces. In fact, that’s partly why figure drawing and portraiture are relatively difficult for artists; simply because your viewers will spot tiny errors that they would never notice in any other subject.
Conversely, our brains have also evolved the ability to discern human features in very simple shapes. Our brains can abstract human-looking details from images that do not accurately depict humans (or even images that are non-living, such as the “Man in the Moon”). The technical name for this phenomenon is pareidolia. Artists can take advantage of this tendency by creating cartoons, which are deliberately not accurate portrayals of the human body, but which we nonetheless accept as credible representations.
I frequently use cartooning techniques in my work, either to provide a lighthearted feel to an article, or else simply to save time! The example below shows an illustration for an early multimedia title that I created, which was intended to help owners of PCs understand and upgrade their systems. This was not a humorous eBook: it was intended to provide useful and serious information.
PC Secrets Title Cartoon
Clearly, this is not a realistic image, but the average viewer understands it quickly, and it serves its purpose in showing the intention of the associated content.
Summary
Even in technical illustration, it’s sometimes desirable to include human figures, either completely or partially. Drawing accurate figures requires significant skill, and can be time-consuming. Quicker alternatives include storyboard-style sketching, and cartooning. I’ve explained why cartoon-style drawing should be considered even when illustrating “serious” technical work.
This article discusses the distinctions between the old and new Microsoft Office file formats, and explains the advantages of choosing the new formats, which are called the Office Open XML file formats. Confusingly, the Office Open XML formats are not the same as the OpenOffice XML file formats. The naming similarity causes much confusion, and arises from the fact that the goals of both definitions were similar, even though the implementations are distinct.
This article also explains how you can decompress a Word file that has been stored using the new XML format and examine its content directly. This can sometimes be helpful if you find that you cannot open a file because it has been corrupted, in which case you may be able to fix the error and make the file once again editable.
In an earlier post, I mentioned the new file format for Microsoft Word files (i.e., files with a .docx extension), which stores data using XML, instead of the binary data coding that was used by the original Microsoft Word format (files with a .doc extension). In fact, that is true not only for .docx files, but also for various other file types created using recent versions of Microsoft’s Office suite of programs. For example, Microsoft Excel files have a new .xlsx format, replacing the older .xls format.
In my earlier post, I also mentioned the general dangers of using proprietary file formats (for any application), because the data contained in the files can only be accessed via the one specific application that’s designed to open files in that format. If the application becomes unavailable, or if the manufacturer changes the program to the point where it is no longer able to open files that use its own older formats, you may have no way to access data in files with the proprietary format. This could result in a severe loss of data at some future time.
To avoid this situation, it’s better whenever possible to store data using open file formats.
Just in case you think that, by extolling the advantages of the Office Open XML file formats here, I’m acting as a “shill” for Microsoft, rest assured that I’m not. In fact, if you read on, you’ll discover why using these new formats can actually free you from dependence on Microsoft’s applications.
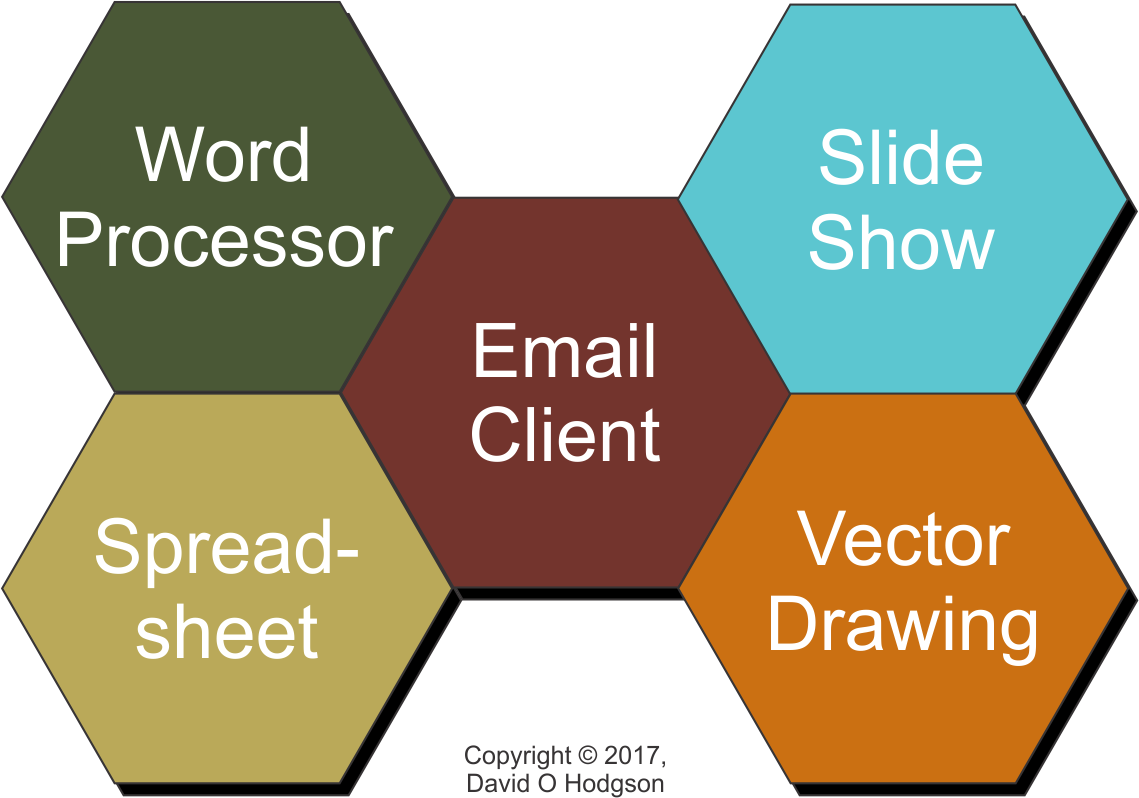
Office Productivity Suites
Over the years, it has become apparent that certain types of application program have widespread usefulness in office environments across many industries. The exact list varies, but in general the following program types are used by typical office computer users:
Typical Components of an Office Software Suite
Word Processor
Spreadsheet
Email Client
Slide Show Generator
Vector Drawing
Software manufacturers have grouped together these commonly-used programs, and offer them as “office productivity suites” with varying levels of integration between the component programs within the suite.
The continued popularity of Microsoft Office is perhaps surprising, because the software is by no means free, and in fact there are good-quality free alternatives available. In this article, I won’t discuss the psychology of why so many people continue to pay to use a piece of software when there are equivalent free alternatives available. However, I will mention some of the alternatives, and show you how the Open XML file formats allow you to use those more easily.
Incidentally, it’s not my intention in this article to discuss the general use of Office suite software in “IT” environments. I don’t work in the field of “IT” (in the sense that the term is typically used), but I do use Office suite software in my roles as author and programmer.
Why were the XML Formats Developed?
I haven’t found any clear statement of the motivation that prompted Microsoft to consider replacing its long-standing binary file formats with XML-based formats. However, I suspect that the primary motivations were competition and pressure from large users of the Office suite.
Given the prevalence of Microsoft Office on computer systems around the world, around the year 2000, many government and official bodies were becoming concerned about the amount of vital information that was being stored in files using the Microsoft binary formats. The problem wasn’t merely the risk that files could become corrupt or unreadable. There was also concern that it was impossible to be certain that the proprietary data formats didn’t include “back doors” that would permit the reading of content that was supposed to be secure.
At the same time, open-source software was being developed to provide free alternatives to the more popular applications in the Microsoft Office suite. The most prominent of these open-source suites was OpenOffice, developed by Sun Microsystems. Although OpenOffice supported the Microsoft binary file formats, it also had its own set of XML-based formats, conforming to the public OpenOffice XML standards.
As a result of these developments, Microsoft offered its own version of open XML-based format specifications, and sought international certification of those formats. The result is that both sets of standards are now publicly available.
Advantages of the XML Formats
Files are more compact. In most cases, if you compare the size of an Office file saved in the binary format, with the same file saved in the equivalent Open XML format, the XML-formatted file will be smaller. This is largely because of the compression applied to the Open XML files. However, files that contain a large number of graphics may not be smaller, because the graphics cannot be further compressed by the zip algorithm.
Easier corrupted file recovery.
Easier to locate and parse content.
Files can be opened and edited with any XML editor.
Files containing macros are easier to identify.
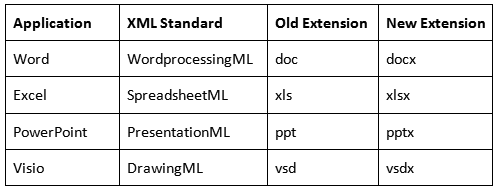
Formats & Applications
The Office Open XML formats correspond to the Office applications as shown in the table below:
Office File Formats
How To Examine the Contents of a Word docx File
When you use Word (or an equivalent word processor) to open a file that uses one of the XML file formats, such as a Word docx file, all you see is a view of the document itself, complete with all its formatting. There seems to be no evidence of any XML structure.
If this is an XML-encoded file, then where is the XML? How do you actually access the XML that defines the document?
In fact, all files that use any of the Office XML formats compress all the XML and component parts into one “zip” file. You can, of course, compress other files into “zip” files, but, when you do, the resulting file typically has the extension .zip.
In fact, Office XML files are indeed zip files, and can have a valid .zip extension. To be able to view and even extract the internal XML and other components, you simply have to open the file using a zip extraction program, instead of a Microsoft Office program. In Windows, the easiest way to do that is to give the Office file a .zip extension.
The following procedure explains exactly how to do this under Windows. Note that this is not an “undocumented hack”; Microsoft encourages you to access the components of the documents this way. These instructions are available from Microsoft at: https://msdn.microsoft.com/en-us/library/aa982683(v=office.12).aspx
Add a .zip extension to the end of the file name, before the .docx
Double-click the file. It will open in the ZIP application. You can see the parts that comprise the file.
Extract the parts to the folder that you created previously.
Non-Microsoft Support for the XML Formats
Many people seem to assume that, if they receive a file in one of the Microsoft Office file formats (either the older proprietary formats or the newer XML formats), then they must use Microsoft Office to open and edit it.
In fact, that’s not true, because the available competitor office suites can handle many of the Microsoft formats well. OpenOffice and Libre Office can both edit files in many of the Microsoft Office formats. Additionally, modern versions of Microsoft Office can at least open files in many of the OpenOffice XML formats, even if it does not fully support them. (In all cases there may be minor formatting differences, and you shouldn’t swap between formats unnecessarily.)
Thus, using the new Office Open XML file formats does not restrict you to using only Microsoft-supplied applications. Files in these formats can be expected to be reasonably “future-proof” for a long time to come.
Deficiencies of the Office Open XML Formats
I am not aware of any major deficiencies of the new formats that would dissuade anyone from using them in preference to the previous binary formats. Here are some relatively minor issues to consider:
Some files containing large quantities of graphics may be larger than in the equivalent binary format.
Files in the new Open XML formats cannot be opened using old (pre-2007) versions of Office.
The XML structure is such that it’s not easy to parse the content of the files in useful ways.
Structure Example
Here’s an example of the actual Word XML markup for a very simple text document. The example shows how revisions to the markup are stored in the file, which can make it difficult to parse the XML content to extract meaningful information.
I wrote a very simple text file, which includes the line of “Normal”-styled text: “This is just a test.”.
In the WordML XML, this appears as:
<w:r><w:t>This is just a test.</w:t></w:r>
Next, I deliberately introduced a revision, by typing some extra characters before the final “t” of “test”, then deleting the extra characters and saving the result. The resulting XML looks like this:
<w:r><w:t>This is just a tes</w:t></w:r><w:bookmarkStart w:id="0" w:name="_GoBack"/><w:bookmarkEnd w:id="0"/><w:r w:rsidR="0000364D"><w:t>t</w:t></w:r><w:r w:rsidR="003F3CE4"><w:t>.</w:t></w:r>
As you can see, the final “t” and the period are now in separate <w:t> elements, and a new bookmark has been inserted. This type of element-splitting makes it difficult to extract the actual text from the XML.
Therefore, before attempting any processing of an Office Open XML-formatted file, you should always “Accept all changes” to eliminate version-tracking markup.
Recommendations
Always use the new XML Office formats rather than the old binary formats when possible.
Even if you have Microsoft Office installed, consider installing LibreOffice, etc., on the same computer. You’ve nothing to lose.
The word “palette” (or “pallet”) has several meanings: it can refer to a tray used to transport items, or to a board used by artists to mix colors (as shown in the fantasy illustration above, which I produced many years ago for a talk on Computer Artwork). In this article, I’ll discuss the principles of Digital Color Palettes. If you’re working with digital graphics files, you’re likely to encounter “palettes” sooner or later. Even though the use of palettes is less necessary and less prevalent in graphics now than it was years ago, it’s still helpful to understand them, and the pros and cons of using them.
I discussed the distinction between bitmap and vector representations in a previous post [The Two Types of Computer Graphics]. Although digital color palettes are more commonly associated with bitmap images, vector images can also use them.
The Basic Concept
A digital color palette is essentially just an indexed table of color values. Using a palette in conjunction with a bitmap image permits a type of compression that reduces the size of the stored bitmap image.
In A Trick of the Light, I explained how the colors you see on the screen of a digital device display, such as a computer or phone, are made up of separate red, green and blue components. The pixels comprising the image that you see on-screen are stored in a bitmap matrix somewhere in the device’s memory.
In most modern bitmap graphic systems, each of the red, green and blue components of each pixel (which I’ll also refer to here as an “RGB Triple” for obvious reasons) is represented using 8 bits. This permits each pixel to represent one of 224 = 16,777,216 possible color values. Experience has shown that this range of values is, in most cases, adequate to allow images to display an apparently continuous spectrum of color, which is important in scenes that require smooth shading (for example, sky scenes). Computers are generally organized to handle data in multiples of bytes (8 bits), so again this definition of an RGB triple is convenient. (About twenty years ago, when memory capacities were much smaller, various smaller types of RGB triple were used, such as the “5-6-5” format, where the red and blue components used 5 bits and the green component 6 bits. This allowed each RGB triple to be stored in a 16-bit word instead of 24 bits. Now, however, such compromises are no longer worthwhile.)
There are, however, many bitmap images that don’t require the full gamut of 16,777,216 available colors. For example, a monochrome (grayscale) image requires only shades of gray, and in general 256 shades of gray are adequate to create the illusion of continuous gradation of color. Thus, to store a grayscale image, each pixel only needs 8 bits (since 28 = 256), instead of 24. Storing the image with 8 bits per pixel (instead of 24 bits) reduces the file size by two-thirds, which is a worthwhile size reduction.
Even full-color images may not need the full gamut of 16,777,216 colors, because they have strong predominant colors. In these cases, it’s useful to make a list of only the colors that are actually used in the image, treat the list as an index, and then store the image using the index values instead of the actual RGB triples.
The indexed list of colors is then called a “palette”. Obviously, if the matrix of index values is to be meaningful, you also have to store the palette itself somewhere. The palette can be stored as part of the file itself, or somewhere else.
To restate, whether implemented in hardware or software, an image that uses a palette does not store the color value of each pixel as an actual RGB triple. Instead, each color value is stored as an index to a single entry in the palette. The palette itself stores the RGB triples. You specify the pixels of a palettized* image by creating a matrix of index values, rather than a matrix of the actual RGB triples. Because each index value is significantly smaller than a single triple, the size the resulting bitmap is much smaller than it would be if each RGB triple were stored.
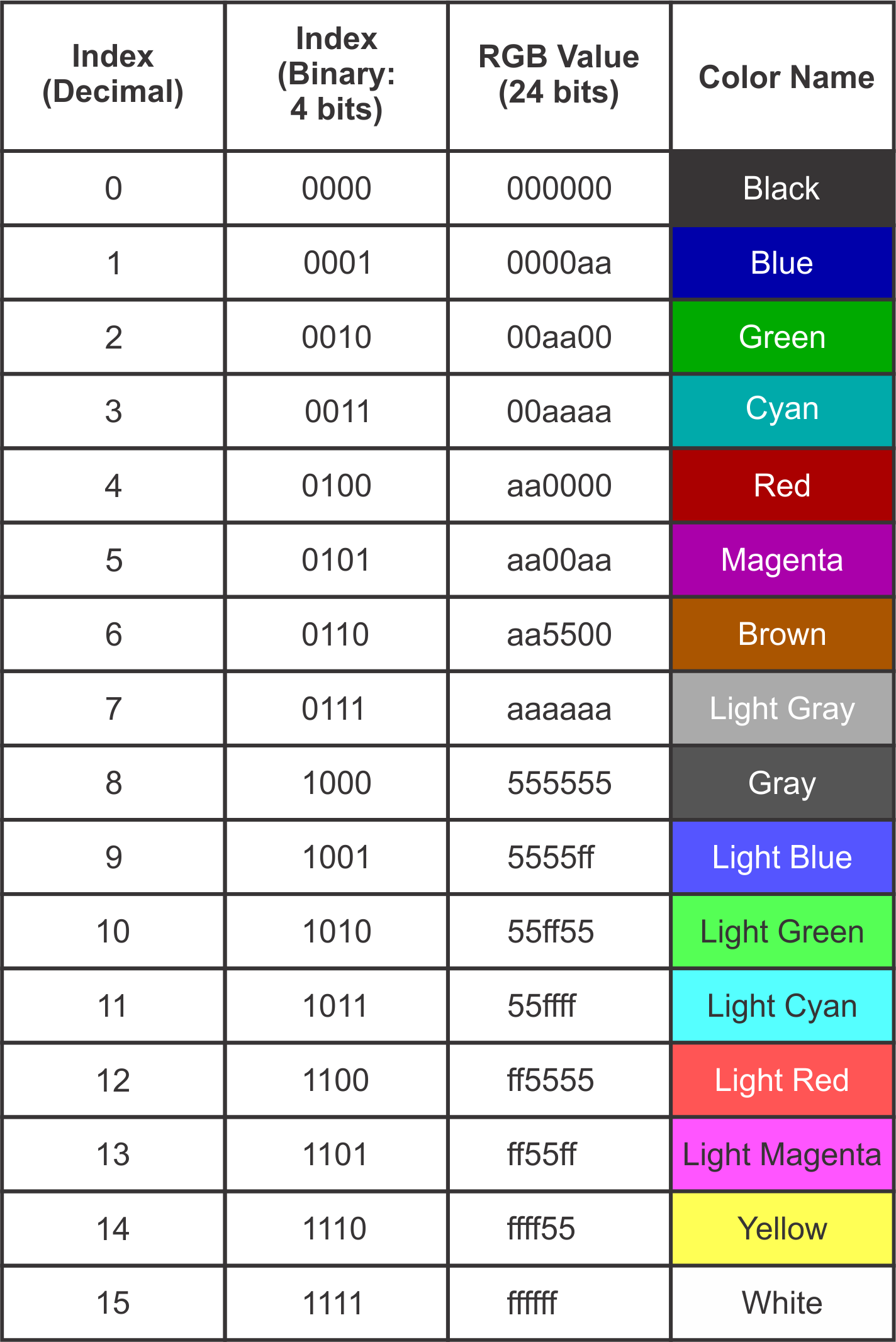
The table below shows the index values and colors for a real-world (albeit obsolete) color palette; the standard palette for the IBM CGA (Color Graphics Adapter), which was the first color graphics card for the IBM PC. This palette specified only 16 colors, so it’s practical to list the entire palette here.
CGA Color Palette Table
(* For the action associated with digital images, this is the correct spelling. If you’re talking about placing items on a transport pallet, then the correct spelling is “palletize”.)
Aesthetic Palettes*
In this context, a palette is a range of specific colors that can be used by an artist creating a digital image. The usual reason for selecting colors from a palette, instead of just choosing any one of the millions of available colors, is to achieve a specific “look”, or to conform to a branding color scheme. Thus, the palette has aesthetic significance, but there is no technical requirement for its existence. The use of aesthetic palettes is always optional.
(* As I explained in Ligatures in English, this section heading could have been spelled “Esthetic Palettes”, but I personally prefer the spelling used here, and it is acceptable in American English.)
Technical Palettes
This type of palette is used to achieve some technological advantage in image display, such as a reduction of the amount of hardware required, or of the image file size. Some older graphical display systems require the use of a color palette, so their use is not optional.
Displaying a Palettized Image
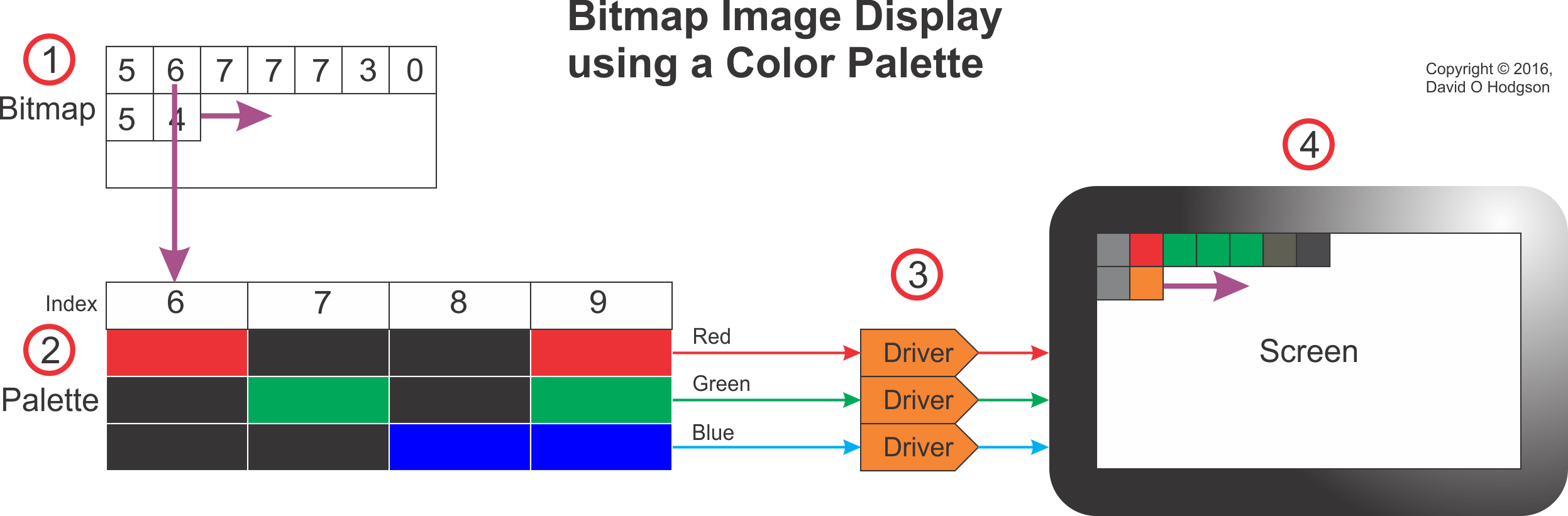
The image below shows how a palettized bitmap image is displayed on a screen. The screen could be any digital bitmap display, such as a computer, tablet or smartphone.
Palette-based Display System
The system works as follows (the step numbers below correspond to the callout numbers in the image):
As the bitmap image in memory is scanned sequentially, each index value in the bitmap is used to “look up” a corresponding entry in the palette.
Each index value acts as a lookup to an RGB triple value in the palette. The correct RGB triple value for each pixel is presented to the Display Drivers.
The Display Drivers (which may be Digital-to-Analog Converters, or some other circuity, depending on the screen technology) create red, green and blue signals to illuminate the pixels of the device screen.
The device screen displays the full-color image reconstituted from the index bitmap and the palette.
Hardware Palette
In the early days of computer graphics, memory was expensive and capacities were small. It made economic sense to maximize the use of digital color palettes where possible, to minimize the amount and size of memory required. This was particularly important in the design of graphics display cards, which required sufficient memory to store at least one full frame of the display. By adding a small special area of memory on the card for use as a palette, it was possible to reduce the size of the main frame memory substantially. This was achieved at the expense of complexity, because now every image that was displayed had to have a palette. To avoid having to create a special palette for every image, Standard color palettes and then Adaptive color palettes were developed; for more details, see Standard vs. Adaptive Palettes below.
One of the most famous graphics card types that (usually) relied on hardware color palettes was the IBM VGA (Virtual or Video Graphics Array) for PCs (see https://en.wikipedia.org/wiki/Video_Graphics_Array).
As the cost of memory has fallen, and as memory device capacities have increased, the use of hardware palettes has become unnecessary. Few, if any, modern graphics cards implement hardware palettes. However, there are still some good reasons to use software palettes.
Software Palette
Generally, the software palette associated with an image is included in the image file itself. The palette and the image matrix form separate sections within one file. Some image formats, such as GIF, require the use of a software palette, whereas others, such as BMP, don’t support palettes at all.
Modern bitmap image formats, such as PNG, usually offer the option to use a palette, but do not require it.
Standard & Adaptive Palettes
Back when most graphics cards implemented hardware palettes, rendering a photograph realistically on screen was a significant problem. For example, a photograph showing a cloud-filled sky would include a large number of pixels whose values are various shades of blue, and the color transitions across the image would be smooth. If you were to try to use a limited color palette to encode the pixel values in the image, it’s unlikely that the palette would include every blue shade that you’d need. In that case, you were faced with the choice of using a Standard Palette plus a technique called Dithering, or else using an Adaptive Palette, as described below.
Standard Palette
Given that early graphics cards could display only palettized images, it simplified matters to use a Standard palette, consisting of only the most commonly-used colors. If you were designing a digital image, you could arrange to use only colors in the standard palette, so that it would be rendered correctly on-screen. However, the standard palette could not, in general, render a photograph realistically—the only way to approximate that was to apply Dithering.
The most commonly-used Standard palette for the VGA graphics card was that provided by BIOS Mode 13H.
Dithering
One technique that was often applied in connection with palettized bitmap images is dithering. The origin of the term “dithering” seems to go back to World War II. When applied to palettized bitmap images, the dithering process essentially introduces “noise” in the vicinity of color transitions, in order to disguise abrupt color changes. Dithering creates patterns of interpolated color values, using only colors available in the palette, that, to the human eye, appear to merge and create continuous color shades. For a detailed description of this technique, see https://en.wikipedia.org/wiki/Dither.
While dithering can improve the appearance of a palettized image (provided that you don’t look too closely), it achieves its results at the expense of reduced image resolution, because of the fact that the dithering of pixel values introduces “noise” into the image. Therefore, you should never dither an image that you want to keep as a “master”.
Adaptive Palette
Instead of specifying a Standard Palette that includes entries for any image, you can instead specify a palette that is restricted only to colors that are most appropriate for the image that you want to palettize. Such palettes are called Adaptive Palettes. Most modern graphics software can create an Adaptive Palette for any image automatically, so this is no longer a difficult proposition.
A significant problem with Adaptive Palettes is that a display device that relies on a hardware palette can typically use only one palette at a time. This makes it difficult or impossible to display more than one full-color image on the screen. You can set the device’s palette to be correct for the first photograph and the image will look great. However, as soon as you change the palette to that for the second photograph, the colors in the first image are likely to become completely garbled.
Fortunately, the days when graphical display devices used hardware palettes are over, so you can use Adaptive Palettes where appropriate, without having to worry about rendering conflicts.
Should you Use Digital Color Palettes?
Palettization of an image is usually a lossy process. As I explained in a previous post [How to Avoid Mosquitoes], you should never apply lossy processes to “master” files. Thus, if your master image is full-color (e.g., a photograph), you should always store it in a “raw” state, without a palette.
However, if you want to transmit an image as efficiently as possible, it may reduce the file size if you palettize the image. This also avoids the necessity to share the high-quality unpalettized master image, which could be useful if you’re posting the image to a public web page.
If it’s obvious that your image uses only a limited color range, such as a monochrome photograph, then you can palettize it without any loss of color resolution. In the case of monochrome images, you don’t usually have to create a custom palette, because most graphics programs allow you to store the image “as 8-bit Grayscale”, which achieves the same result.
In summary, then, in general it’s best not to use palettes for full-color images. However, if you know that your image is intended to contain only a limited color range, then you may be able to save file space by using a palette. Experimentation is sometimes necessary in such cases. You may also want to palettize an image so that you don’t have to make the high-quality original available publicly. If you’re an artist who has created an image that deliberately uses a limited palette of colors, and you want to store or communicate those choices, then that would also be a good reason to use a palettized image.
Back in my schooldays, when studying English Language and English Literature, I sometimes encountered strange characters that looked like combinations of letters. For example, we were encouraged to consult encyclopædias, and I noticed that that word included a mysterious “æ” character. Inexplicably, throughout all that study, none of my teachers ever explained to us the purpose and usage of these characters, which I later learned were called linguistic ligatures.
In this article, I’ll explain what ligature characters are, and how they are or were used in the English language.
The use of some types of ligature character is dying out in English. As I’ll explain, this change seems to have been caused partly by limitations of writing technology.
What is a Ligature?
The word ligature has several meanings, but a linguistic ligature (which is what I’ll be discussing here) is a conjoining of two (or more) letters in writing, which may be done for various reasons.
Linguistic Ligatures serve a variety of purposes:
Typographical
Pronunciation
Shorthand Symbol
This article discusses ligatures as used in the English language, but mentions other languages where these have in some way influenced the English usage.
Maybe my English teachers thought that ignoring ligature characters was reasonable, because they regarded ligatures as a stylistic device only. After all, our English language studies also didn’t discuss other stylistic issues, such as font choice. It’s also true that we were never taught to use ligatures when writing.
In reality, however, the use of ligatures is more than simply a matter of typographic style. In the past, and even sometimes today, in English and in other languages, ligatures are or have been used as letters in their own right. There has been much evolution over time, as some symbols that were originally ligatures have been transformed into letters.
Typographic Ligatures
Typographic ligatures are used in typesetting, to optimize the spacing and interaction between letters. This kind of ligature has no linguistic significance; it has no effect on pronunciation or meaning.
Perhaps one of the best-known examples of this kind of ligature is “fi”, which is used to close the space between “fi” when printed, in such a way that the hook of the “f” doesn’t collide with the dot of the “i”.
Linguistic Ligature Letters
Conversely, linguistic ligatures do affect the pronunciation and meaning of words. The following are some examples of existing or former linguistic ligature characters that you may encounter in English.
W
There is one letter in English that was originally not a letter but a ligature: w. The fact that it was originally two letters is indicated by its name: “double u”. As I mentioned in a previous post, the sound represented by “w” did not exist in Latin, which presented a problem when scribes writing English wanted to switch from using runic letters to the Latin alphabet. Various workarounds were invented, such as retaining the runic character wynn to represent “w” in English, but, eventually, the “Wessex convention” of representing “w” with two “v” characters became the standard.
The Æsc and the Œthel
Æsc. The ligature æ has had various uses over the centuries.
In Latin, ae was a letter combination that was pronounced as a diphthong “ai”, similar to the “long I” in the modern English word “fine”. Later, the pronunciation changed to a simple vowel “e” as in “men”, so it became the practice to write the letter combination as a ligature.
In the Old English language, æ was a separate letter called æsc (pronounced “ash”, and meaning ash, as in the type of tree). In Old English, the letters “æ” and “a” had consistent and different pronunciations. The letter “æ” was always pronounced as the “a” in the modern word “man”, whereas the letter “a” was always pronounced as the vowel sound in the modern word “palm”.
The usual pronunciation of this character in modern English is “ee”.
Œthel. This ligature character is generally used in English for words imported from Greek, for example, “Œdipus”. Its usual pronunciation in modern English is “ee”.
This character also corresponds to a runic character called ēðel, meaning “estate”. In Latin, it was used to represent the Greek diphthong “oi”, and hence pronounced as in “coil”.
In American English, this ligature has been replaced with “e” in most cases. However, there are some exceptions, such as “phoenix”.
This ligature also appears in many modern French words. For example, “œil” for “eye” and “œuf” for “egg”.
Ampersand (&)
The Ampersand character & is actually also a contorted ligature of the letters “et”, which formed the Latin word for “and” (and is still the French word for “and”).
In a previous post I described several obsolete characters that appear in a surviving Old English inscription above the doorway of St. Gregory’s Minster in Yorkshire, England. One character that appears in that inscription, but which I didn’t discuss in that post, is the Tironian Et, which was used as shorthand for the word “and” in the days before the use of the ampersand became common.
The Tironian Et is not represented in most Unicode typefaces, so here it is in graphic form:
The Tironian Et is not a ligature, but I’m mentioning it here because of its relation to the ampersand.
Eszett (ß)
Eszett is not a modern English character, but forms of it sometimes appear in older English texts, where it represents a double s (“ss”), written as a “long s” and a standard s.
Note that, despite the resemblance, the eszett character is not the same character as the Greek lower-case beta: β (and obviously does not have the same pronunciation). I mention this because, even in printed documents, I sometimes see cases where one character has mistakenly been used in place of the other.
Modern Evolution of Linguistic Ligatures
Several technological advances have led to a decline in the use of ligatures during the past century:
Typewriters did not support ligatures, which led to their replacement with the corresponding letter pairs.
ASCII character encoding did not include symbols for ligatures.
In the English language, the use of ligatures has tended to die out further during the past twenty years, but the convention for the replacement of the ligatures varies across the English-speaking world.
In British/International English, the ligatures have usually been replaced by the two-letter combinations that formed the ligature, e g., æ -> ae. For example, anæsthesia has become anaesthesia.
In American English, only the second letter is usually retained, e.g., æ -> e. For example, the word æsthetic has come to be spelled aesthetic in British English, but (sometimes) esthetic in American English (which could make it tricky to look up in a dictionary). Similarly, anæsthesia has become anesthesia.
Unicode character encoding does support ligatures (for fonts that provide the appropriate glyphs), but these characters usually cannot be entered via the keyboard, so most writers don’t use ligature characters, because of the inconvenience involved.
Linguistic Ligatures & Unicode
Many Unicode typefaces provide glyphs for ligatures, so you can replace letter combinations with ligatures. This is true for both linguistic and typographical ligatures. Some applications, such as Word, can make these replacements automatically.
For the linguistic ligatures and ligature-derived characters discussed here, but which are not available on standard keyboards, the following are the Unicode code points.
Character
Name
Code Point (Upper Case)
Code Point (Lower Case)
Æ
Æsc
U+00C6
U+00E6
Œ
Œthel
U+0152
U+0153
ß
Eszett
U+0392
U+03B2
Tironian Et
U+204A*
–
* Not supported in common Unicode typefaces, but available in Segoe UI Symbol, which is pre-installed in Windows.
Remember that, even if you’re using a typeface that provides glyphs for these Unicode characters, the equivalent two-letter combinations will not automatically be replaced with the ligature character as you type, unless your application (e.g., Word) is set up to do that.
Summary: Forget about Linguistic Ligatures!
Based on the considerations above, present-day writers of the English language will probably never need to use linguistic ligatures. In general, if you encounter “æ” you can treat it as “ae”, and if you encounter “œ”, you can treat it as “oe”.
Nonetheless, you will sometimes encounter these characters in older or more formal publications, so it’s helpful to know what they are, and how to pronounce them.
It’s also helpful to understand the way that these characters have been replaced over time, so you can see why, for example, the word “aesthetic” may sometimes be spelled “esthetic”.
References & Acknowledgments
The typeface used in the heading illustration for this article is “King Harold”, which is available for free download from:
When scanning the news, I often see articles with titles such as, “The nation needs more programmers”, “The nation needs to increase the number of STEM graduates”, and so on. However, this is a simplistic idea for many reasons. I don’t plan to examine all the reasons in this article, but I do want to discuss the notion that “any kind of programming will do” and explain the reasons to avoid Spaghetti Code.
It seems that most non-programmers simply assume that “all programs are created equal”, in the sense that all code is of equivalent quality. Unfortunately, that is by no means the case. To be clear, the quality of the code has nothing to do with whether the intention of a program is “good” or “bad” (i.e., malware). A malicious program may be of very high quality, whereas a well-intentioned program may be badly written.
Recognition of the problems caused by poor quality programs over the past few decades has led to advances in the structure of programs. These structures are not necessary for the correct operation of a program, but they make the program much easier for humans to understand and maintain, and thus the code has much greater and more enduring value.
The Evolution of Programming Structure
Largely as a result of bitter experience, the discipline of programming has evolved rapidly over the past few decades. Some code that conforms to what was considered acceptable programming practice in, say, the 1980s would be regarded as appallingly inept today.
In the early days, it was considered sufficient just to write code that produced the desired result. There was very little consideration of how the code was implemented, and in any case the available coding tools were quite primitive.
However, it soon became apparent that merely having code that worked wasn’t adequate, because sooner or later the code would need to be modified. If the code had been implemented in a disorganized way, possibly by a programmer who had since moved onto other projects, the maintenance task became nightmarishly difficult. This realization led to the development of the principles of Structured Programming, then Object-Oriented Programming, and other more sophisticated approaches.
There isn’t space in this article to discuss the detailed history of programming structures and paradigms. For much more detail, see, for example, https://en.wikipedia.org/wiki/Structured_programming. Here, I just want to provide an example of why programming structure is so important.
Early programming languages had very limited control structures. Perhaps the most common situation in program writing is when the code must perform a test, and then take actions based on the result of the test.
The earliest programs were written in machine code. Even the use of Assembly code (which used mnemonics to describe machine instructions) offered limited control structures, which usually consisted of jumping to one code address or another, depending on the result of a test.
“High Level Languages” were created to make programming more efficient, and to offer more sophisticated control structures. However, some high-level languages still retained the GoTo instruction, which permitted unstructured jumps in the control flow.
When an error was discovered, or when it became necessary to change the code’s operation, the existence of all these jumps made it very difficult to trace through the sequence of programming steps. For obvious reasons, such code has come to be known as Spaghetti Code. If you see code that contains such instructions such as GoTo or GoSub (used in Visual Basic), then you’re probably looking at Spaghetti Code.
The deficiencies of Spaghetti Code led to the development of Structured Programming, where code is divided up into clearly defined modules, and control flow is determined by looping and branching constructs that make it much easier to follow the operation of a program. Later on, more sophisticated programming paradigms were developed, such as Object-Oriented Programming. These paradigms not only eliminated the Spaghetti Code, but also offered other advantages. The important point is that these paradigms were developed to make programming easier and more productive, so it really isn’t the case that writing Spaghetti Code is somehow simpler.
Not The State of the Art: A Horrifying Example of Spaghetti Code!
I’d like to be able to state that spaghetti code and its attendant nightmares are nothing but memories of the past, and that nobody would dream of writing Spaghetti Code today.
Unfortunately, that’s not universally true, and I still sometimes encounter such code today, as in the following example written in the Microsoft VBA (Visual Basic for Applications) language, which was intended for processing the content of Microsoft Word documents.
Lest you think that the following example is something I made up (“Surely nobody would really write code like this”), I assure you that this is real code that I excerpted from a VBA program that was being relied on by many users. All that I’ve done is to change some function and label names, to protect the guilty!
The purpose of this function is to find and select the first heading in a Word document (that is, the first paragraph of text with any of the styles Heading 1 through Heading 9). When this heading has been found, the code checks to see whether it contains the text “Heading Before”. If it does, the code jumps to the next heading in the document, and examines the style of that heading. If the style of the following heading is not “Heading 1”, then a new Heading 1-styled heading is inserted, with the text “Heading Inserted”. (Don’t worry about why it would be necessary to do this; rest assured that this was claimed to be necessary in the code on which I based this example!)
Notice particularly the statement GoTo InsertHeadingOne and its associated label InsertHeadingOne.
Sub insert_Heading1()
Call Select_First_Heading_in_Doc
With Selection
If .Paragraphs(1).Range.Text Like "Heading Before" Then
.GoToNext what:=wdGoToHeading
GoTo InsertHeadingOne
Else
InsertHeadingOne:
If Not .Paragraphs(1).Style = "Heading 1" Then
.MoveLeft
.TypeText vbCr & "Heading Inserted" & vbCr
.Paragraphs(1).Style = "Normal"
.MoveLeft
.Paragraphs(1).Style = "Heading 1"
End If
End If
End With
End Sub
This is such a short subroutine that an experienced programmer would think it should be possible to write it withoutGoTo instructions and labels. That is correct; it is possible, and the result is much more succinct, as I show below.
Let’s examine the subroutine’s control flow. The code selects the first text in the document that has any Word “Heading” style. Then, it evaluates the “If” statement. If the evaluation is true, then the selection is moved to the next heading, following which the “Else” code is evaluated! In other words, the code within the “Else” clause is executed whatever the result of the “If” expression, and thus doesn’t need to be within an “Else” clause at all.
The following code is functionally identical to that above, but does not require either GoTo instructions or the spurious “Else” clause.
Sub insert_Heading1()
Call Select_First_Heading_in_Doc
With Selection
If .Paragraphs(1).Range.Text Like "Heading Before" Then
.GoToNext what:=wdGoToHeading
End If
If Not .Paragraphs(1).Style = "Heading 1" Then
.MoveLeft
.TypeText vbCr & "Heading Inserted" & vbCr
.Paragraphs(1).Style = "Normal"
.MoveLeft
.Paragraphs(1).Style = "Heading 1"
End If
End With
End Sub
This example gives the lie to the excuse that “we have to write spaghetti code because it’s more compact than structured code”, since the structured and well-organized version is clearly shorter than the spaghetti code version.
This example doesn’t include the use of the GoSub instruction, which is another “relic” from pre-structured programming days. GoSub offers a very primitive form of subroutine calling, but should always be avoided in favor of actual subroutine or function calls.
The Race to the Bottom
The issue of software quality frequently sets up an ongoing conflict between programmers and clients (or between employees and employers).
Clients or employers want to produce working code as quickly and as cheaply as possible. The problem with this is that it’s a short-sighted approach that frequently turns out to be a false economy in the long term. Cheap programmers tend to be inexperienced, and so produce poor quality code. Rushing code development leads to implementations that are not well thought out. The result of the short-sighted approach is that the code requires a disproportionate level of bug fixing and maintenance, or else has to be rewritten completely before the end of its anticipated lifetime.
Avoiding the Horror of Spaghetti Code
In summary, then, the message I want to offer here is this. If you’re going to write software, or hire someone else to write software for you, then you should make it your business to understand what constitutes high-quality software, and then take the time, effort and expense to ensure that that is what gets produced. Unfortunately, I realize that many software producers will continue to ignore this recommendation, but that doesn’t make it any less true.
I regularly use MadCap Flare for the production of technical documentation. Flare is a sophisticated content authoring tool, which stores all its topic and control files using XML. This makes it relatively easy to process the content of the files programmatically, as in the example of CSS class analysis that I described in a previous post.
The Flare software is based on Microsoft’s .NET framework, so the program runs only under Windows. For that reason, this discussion will be restricted to Windows file systems.
In Windows, the “path” to a file consists of a hierarchical list of subfolders beneath a root volume, for example:
c:\MyRoot\MyProject\Content\MyFile.htm
Sometimes, however, it’s convenient to specify a path relative to another location. For example, if the file at:
contained a link to MyFile.htm as above, the relative path could be specified as:
..\MyTopic.htm
In the syntax of relative paths, “..” means “go up one folder level”. Similarly, “.” means “this folder level”, so .\MyFile.htm refers to a file that’s in the same folder as the file containing the relative path.
If you’ve ever examined the markup in Flare files, you’ll have noticed that extensive use is made of “relative paths”. For example, a Flare topic may contain a hyperlink to another topic in the same project, such as:
Similarly, Flare’s Table-Of-Contents (TOC) files (which have .fltoc extensions) are XML files that contain trees of TocEntry elements. Each TocEntry element has a Link attribute that contains the path to the topic or sub-TOC that appears at that point in the TOC. All the Link attribute paths start at the project’s Content (for linked topics) or Project (for linked sub-TOCs) folder, so in that sense they are relative paths.
When I’m writing code to process these files (for example to open and examine each topic in a Flare TOC file), I frequently have to convert Flare’s relative paths into absolute paths (because the XDocument.Load() method, as described in my previous post, will accept only an absolute path), and vice versa if I want to insert a path into a Flare file. Therefore, I’ve found it very useful to create “library” functions in C# to perform these conversions. I can then call the functions AbsolutePathToRelativePath() and RelativePathToAbsolutePath() without having to think again about the details of how to convert from one format to the other.
I’m sure that there are probably similar functions available in other programming languages. For example, I’m told that Python includes a built-in conversion function called os.path.relpath, which would make it unnecessary to create custom code. Anyway, my experience as a programmer suggests that you can never have too many code samples, so I’m offering my own versions here to add to the available set. I have tested both functions extensively and they do work as listed.
The methods below are designed as static methods for inclusion in a stringUtilities class. You could place them in any class, or make them standalone functions.
AbsolutePathToRelativePath
This static method converts an absolute file path specified by strTargFilepath to its equivalent path relative to strRootDir. strRootDir must be a directory tree only, and must not include a file name.
For example, if the absolute path strTargFilepath is:
c:\folder1\folder2\subfolder1\filename.ext
And the root directory strRootDir is:
c:\folder1\folder2\folder3\folder4
The method returns the relative file path:
..\..\subfolder1\filename.ext
Note that there must be some commonality between the folder tree of strTargFilepath and strRootDir. If there is no commonality, then the method just returns strTargFilepath unchanged.
The path separator character that will be used in the returned relative path is specified by strPreferredSeparator. The default value is correct for Windows.
using System.IO;
public static string AbsolutePathToRelativePath(string strRootDir, string strTargFilepath, string strPreferredSeparator = "\\")
{
if (strRootDir == null || strTargFilepath == null)
return null;
string[] strSeps = new string[] { strPreferredSeparator };
if (strRootDir.Length == 0 || strTargFilepath.Length == 0)
return strTargFilepath;
// Convert to arrays
string[] strRootFolders = strRootDir.Split(strSeps, StringSplitOptions.None);
string[] strTargFolders = strTargFilepath.Split(strSeps, StringSplitOptions.None);
if (string.Compare(strRootFolders[0], strTargFolders[0], StringComparison.OrdinalIgnoreCase) != 0)
return strTargFilepath;
// Count common root folders
int i = 0;
List<string> listRelFolders = new List<string>();
for (i = 0; i < strRootFolders.Length; i++)
{
if (string.Compare(strRootFolders[i], strTargFolders[i], StringComparison.OrdinalIgnoreCase) != 0)
break;
}
for (int k = i; k < strTargFolders.Length; k++)
listRelFolders.Add(strTargFolders[k]);
System.Text.StringBuilder sb = new System.Text.StringBuilder();
if (i > 0)
{
// Note: the last element of strTargFolders is actually the filename, so must adjust count for that
for (int j = 0; j < strRootFolders.Length - i; j++)
{
sb.Append("..");
sb.Append(strPreferredSeparator);
}
}
return sb.Append(string.Join(strPreferredSeparator, listRelFolders.ToArray())).ToString();
}
RelativePathToAbsolutePath
This static method converts a relative file path specified by strTargFilepath to its equivalent absolute path using strRootDir. strRootDir must be a directory tree only, and must not include a file name.
For example, if the relative path strTargFilepath is:
..\..\subfolder1\filename.ext
And the root directory strRootDir is:
c:\folder1\folder2\folder3\folder4
The method returns the absolute file path:
c:\folder1\folder2\subfolder1\filename.ext
If strTargFilepath starts with “.\” or “\”, then strTargFilepath is simply appended to strRootDir
The path separator character that will be used in the returned relative path is specified by strPreferredSeparator. The default value is correct for Windows.
using System.IO;
public static string RelativePathToAbsolutePath(string strRootDir, string strTargFilepath, string strPreferredSeparator = "\\")
{
if (string.IsNullOrEmpty(strRootDir) || string.IsNullOrEmpty(strTargFilepath))
return null;
string[] strSeps = new string[] { strPreferredSeparator };
// Convert to lists
List<string> listTargFolders = strTargFilepath.Split(strSeps, StringSplitOptions.None).ToList<string>();
List<string> listRootFolders = strRootDir.Split(strSeps, StringSplitOptions.None).ToList<string>();
// If strTargFilepath starts with .\ or \, delete initial item
if (string.IsNullOrEmpty(listTargFolders[0]) || (listTargFolders[0] == "."))
listTargFolders.RemoveAt(0);
while (listTargFolders[0] == "..")
{
listRootFolders.RemoveAt(listRootFolders.Count - 1);
listTargFolders.RemoveAt(0);
}
if ((listRootFolders.Count == 0) || (listTargFolders.Count == 0))
return null;
// Combine root and subfolders
System.Text.StringBuilder sb = new System.Text.StringBuilder();
foreach (string str in listRootFolders)
{
sb.Append(str);
sb.Append(strPreferredSeparator);
}
for (int i = 0; i < listTargFolders.Count; i++)
{
sb.Append(listTargFolders[i]);
if (i < listTargFolders.Count - 1)
sb.Append(strPreferredSeparator);
}
return sb.ToString();
}
[7/1/16] Note that the method above does not check for the case where a relative path contains a partial overlap with the specified absolute path. If required, you would need to add code to handle such cases.
For example, if the relative path strTargFilepath is:
folder4\subfolder1\filename.ext
and the root directory strRootDir is:
c:\folder1\folder2\folder3\folder4
the method will not detect that folder4 is actually already part of the root path.
In this post, I’m going to explain how you can avoid mosquitoes. However, if you happen to live in a humid area, I’m afraid my advice won’t help you, because the particular “mosquitoes” I’m talking about are undesirable artifacts that occur in bitmap images.
For many years now, my work has included the writing of user assistance documents for various hardware and software systems. To illustrate such documents, I frequently need to capture portions of the display on a computer or device screen. As I explained in a previous post, the display on any device screen is a bitmap image. You can make a copy of the screen image at any time for subsequent processing. Typically, I capture portions of the screen display to illustrate the function of controls or regions of the software I’m describing. This capture operation seems like it should be simple, and, if you understand bitmap image formats and compression schemes, it is. Nonetheless, I’ve encountered many very experienced engineers and writers who were “stumped” by the problem described here, hence the motivation for my post.
Below is the sample screen capture that I’ll be using as an example in this post. (The sample shown is deliberately enlarged.) As you can see, the image consists of a plain blue rectangle, plus some black text and lining, all on a plain white background.
Screen Capture Example
Sometimes, however, someone approaches me complaining that a screen capture that they’ve performed doesn’t look good. Instead of the nice, clean bitmap of the screen, as shown above, their image has an uneven and fuzzy appearance, as shown below. (In the example below, I’ve deliberately made the effect exceptionally bad and magnified the image – normally it’s not this obvious!)
Poor Quality Screen Capture, with Mosquitoes
In the example above, you can see dark blemishes in what should be the plain white background around the letters, and further color blemishes near the colored frame at the top. Notice that the blemishes appear only in areas close to sharp changes of color in the bitmap. Because such blemishes appear to be “buzzing around” details in the image, they are colloquially referred to as “mosquitoes”.
Typically, colleagues present me with their captured bitmap, complete with mosquitoes, and ask me how they can fix the problems in the image. I have to tell them that it actually isn’t worth the effort to try to fix these blemishes in the final bitmap, and that, instead, they need to go back and redo the original capture operation in a different way.
What Causes Mosquitoes?
Mosquitoes appear when you apply the wrong type of image compression to a bitmap. How do you know which is the right type of compression and which is wrong?
There are many available digital file compression schemes, but most of them fall into one of two categories:
Block Transform Compression
Lossless Huffman & Dictionary-Based Compression
Block Transform Compression Schemes
Most people who have taken or exchanged digital photographs are familiar with the JPEG (Joint Photographic Experts Group) image format. As the name suggests, this format was specifically designed for the compression of photographs; that is, images taken with some type of camera. Most digitized photographic images display certain characteristics that affect the best choice for compressing them. The major characteristics are:
Few sharp transitions of color or luminance from one pixel to the next. Even a transition that looks sharp to the human eye actually occurs over several pixels.
A certain level of electrical noise in the image. This occurs due to a variety of causes, but it has the effect that pixels in regions of “solid” color don’t all have exactly the same value. The presence of this noise adds high-frequency information to the image that’s actually unnecessary and undesirable. In most cases, removing the noise would actually improve the image quality.
As a result, it’s usually possible to remove some of the image’s high-frequency information without any noticeable reduction in its quality. Schemes such as JPEG achieve impressive levels of compression, partially by removing unnecessary high-frequency information in this way.
JPEG analyzes the frequency information in an image by dividing up the bitmap into blocks of 16×16 pixels. Within each block, high-frequency information is removed or reduced. The frequency analysis is performed by using a mathematical operation called a transform. The problem is that, if a particular block happens to contain a sharp transition, removing the high-frequency components tends to cause “ringing” in all the pixels in the block. (Technically, this effect is caused by something called the Gibbs Phenomenon, the details of which I won’t go into here.) That’s why the “mosquitoes” cluster around areas of the image where there are sharp transitions. Blocks that don’t contain sharp transitions, such as plain-colored areas away from edges in the example, don’t contain so much high-frequency information, so they compress well and don’t exhibit mosquitoes.
In the poor-quality example above, you can actually see some of the 16×16 blocks in the corner of the blue area, because I enlarged the image to make each pixel more visible.
Note that the removal of high-frequency information from the image results in lossy compression. That is, some information is permanently removed from the image, and the original information can never be retrieved exactly.
Computer screens typically display bitmaps that have many sharp transitions from one color to another, as shown in the sample screen capture. These images are generated directly by software; they aren’t captured via a camera or some other form of transducer.
If you’re reading this article on a computer screen, it’s likely that the characters you’re viewing are rendered with very sharp black-to-white transitions. In fact, modern fonts for computer displays are specifically designed to be rendered in this way, so that the characters will appear sharp and easy to read even when the font size is small. The result is that the image has a lot of important high-frequency information. Similarly, such synthesized images have no noise, because they were not created using a transducer that could introduce noise.
Applying block-transform compression to such synthesized bitmaps results in an image that, at best, looks “fuzzy” and at worst contains mosquitoes. Text in such bitmaps can quickly become unreadable.
If you consider the pixel values in the “mosquito-free” sample screen capture above, it’s obvious that the resulting bitmap will contain many pixels specifying “white”, many specifying “black”, and many specifying the blue shade. There’ll also be some pixels with intermediate gray or blue shades, in areas where there’s a transition from one color to another, but far fewer of those than of the “pure” colors. For synthesized images such as this, an efficient form of compression is that called Huffman Coding. Essentially, this coding scheme compresses an image by assigning shorter codewords to the pixel values that appear more frequently, and longer codewords to values that are less frequent. When an image contains a large number of similar pixels, the overall compression can be substantial.
Another lossless approach is to create an on-the-fly “dictionary” of pixel sequences that appear repeatedly in the image. Again, in bitmaps that contain regions with repeated patterns, this approach can yield excellent compression. The details of how dictionary compression works can be found in descriptions of, for example, the LZW algorithm.
Unlike many block transform schemes, such compression schemes are lossless. Even though all the pixel values are mapped from one coding to another, there is no loss of information, and, by reversing the mapping, it’s possible to restore the original image, pixel-for-pixel, in its exact form.
One good choice for a bitmap format that offers lossless compression is PNG (Portable Network Graphics). This format uses a two-step compression method, by applying firstly dictionary-based compression, then following that by Huffman coding of the results.
A Mosquito-Free Result
Here is the same screen capture sample, but this time I saved the bitmap as a PNG file instead of as a JPEG file. Although PNG does compress the image, the compression is lossless and there’s no block transform. Hence, there’s no danger that mosquitoes will appear.
High Quality Screen Capture without Artifacts
Avoiding Mosquitoes: Summary
As I’ve shown, the trick to avoiding mosquitoes in screen capture bitmaps or other computer-generated imagery is simply to avoid using file formats or compression schemes that are not suitable for this kind of image. The reality is that bitmap formats were designed for differing purposes, and are not all equivalent to each other.
Unsuitable formats include those that use block-transform and/or lossy compression, such as JPEG.
Suitable formats are those that use lossless Huffman coding and/or dictionary-based compression, or no compression at all, such as PNG.